摘要: 我们研究大语言模型中涌现出的 outlier 的功能角色,重点关注两类现象:attention sinks (少数 token 持续获得很大的 attention logits)与 residual sinks (少数固定维度在大多数 token 上持续呈现很大的激活)。我们提出假设:这些 outlier 与相应的 normalization(例如 softmax attention 与 RMSNorm)协同作用,能够有效地对其他非 outlier 成分进行 rescale。我们将这一现象称为 outlier-driven rescaling ,并在不同模型架构与不同训练 token 数量设置下验证了该假设。该视角统一解释了两类 sink 的起源与缓解方法。我们的主要结论与观察包括:1. Outlier 与 normalization 共同发挥作用 :移除 normalization 会消除相应 outlier,但会显著降低训练稳定性与性能;在保留 normalization 的同时直接 clip outlier 也会导致性能退化,表明 outlier-driven rescaling 对训练稳定性有贡献。2. Outlier 更像 rescale 因子而非直接贡献者 :attention sink 与 residual sink 在最终输出中的实际贡献显著小于非 outlier。3. Outlier 可被吸收到可学习参数中,或通过显式 gated rescaling 进行缓解 :这可带来更好的训练性能(平均提升 2 分)与更强的量化鲁棒性(在 W4A4 quantization 下仅退化 1.2 分)。
1. Introduction
LLM中经常出现一些巨大的Activation数值,这些数值对浮点计算精度有影响、对量化有影响,但是简单地clip这些outlier会导致严重的精度下降。
一种典型的Outlier是Attention Sink,极少数的attention logit显著大于其他部分,导致少量的特殊Token持续获得很高的分数,一般认为Attention Sink与Softmax Normalization相关。近期一些工作表明,这些Sink Token的Value向量的范数小于其他Token,这意味着这些sink token并非凭借异常大的分数主导整个输出,考虑:
attention 输出是,而sink token对应的范数很小,导致最终输出的内容并不以它主导。这种现象暗示模型将该异常 score 作为 softmax normalization 内的 scale 因子来使用,从而实现对 attention 的 rescaling。GatedAttention引入显式的Gating机制完成这种rescaling,降低对attention sink的依赖。
另一类显著的outlier现象是residual中的Massive Activation,与attention sink相关的token会在某些维度上产生巨大的activation,然后又促进后面层的attention sink形成。
上述两种现象有一个共同点,它们都通过normalization发挥作用。我们用 outlier-driven rescaling 来统一描述这种行为:outlier 与 normalization 交互,使得 normalization 之后的非 outlier 成分被 rescale。
本文在residual中验证假设的另一种outlier,这些outlier出现在绝大多数Token的同一组固定维度上。实验证明,这些outlier与attention sink有很多相似处,因此将其命名为residual sink。residual sink并不与特定的输入想绑定,暗示它们并非在传递数据相关的特征。我们进一步验证它们与RMSNorm交互,实现了outlier-driven rescaling。大量实验证据支持此假说,概括如下:
- 移除 normalization会减少 residual sinks,但会损害模型性能与训练稳定性;通过 clipping 或架构修改来抑制 outlier 也会导致退化;
- 在依赖 outlier-driven rescaling 的模型中,RMSNorm 在 outlier 易发维度上的权重长期显著小于均值(例如 0.006 vs. 1),进一步表明这些 outlier 维度主要充当 rescale 因子而非直接贡献者。我们证明:在满足该性质时,RMSNorm 后特征范数的上界会随 outlier 幅度增大而降低;
- residual sink 可被吸收到参数中,类似于将 attention sink 吸收到可学习 bias,从而无需在 residual stream 中显式产生 outlier;
- 若 rescaling 是底层目的,则显式引入 rescaling 机制应减少 outlier。与先前工作中 gating-based rescaling 能减少 attention sinks 一致,我们实验发现:在 RMSNorm 后插入轻量 gating(GatedNorm )可有效缓解 residual sinks,同时保持甚至提升模型性能。outlier 更少、激活更平滑后,GatedNorm 训练的模型也表现出更好的量化性能;
- gating-based rescaling 会降低模型对 outlier 的依赖,从而削弱对“容易诱发 outlier 的架构选择”的敏感性。例如,SwiGLU通常在 FFN 中优于 sigmoid-based GLU,因为它更容易产生更大的激活以支持 outlier-driven rescaling;但加入 gating-based rescaling 后,GLU 能匹配或超过 SwiGLU。
2. Outliers in Large Language Models
考虑一个prenorm Transformer,对于输入长度为的模型,模型首先做embedding:,然后经过层处理,Layer i记作,由于有Residual,更新为:
本文的主要研究对象就是。
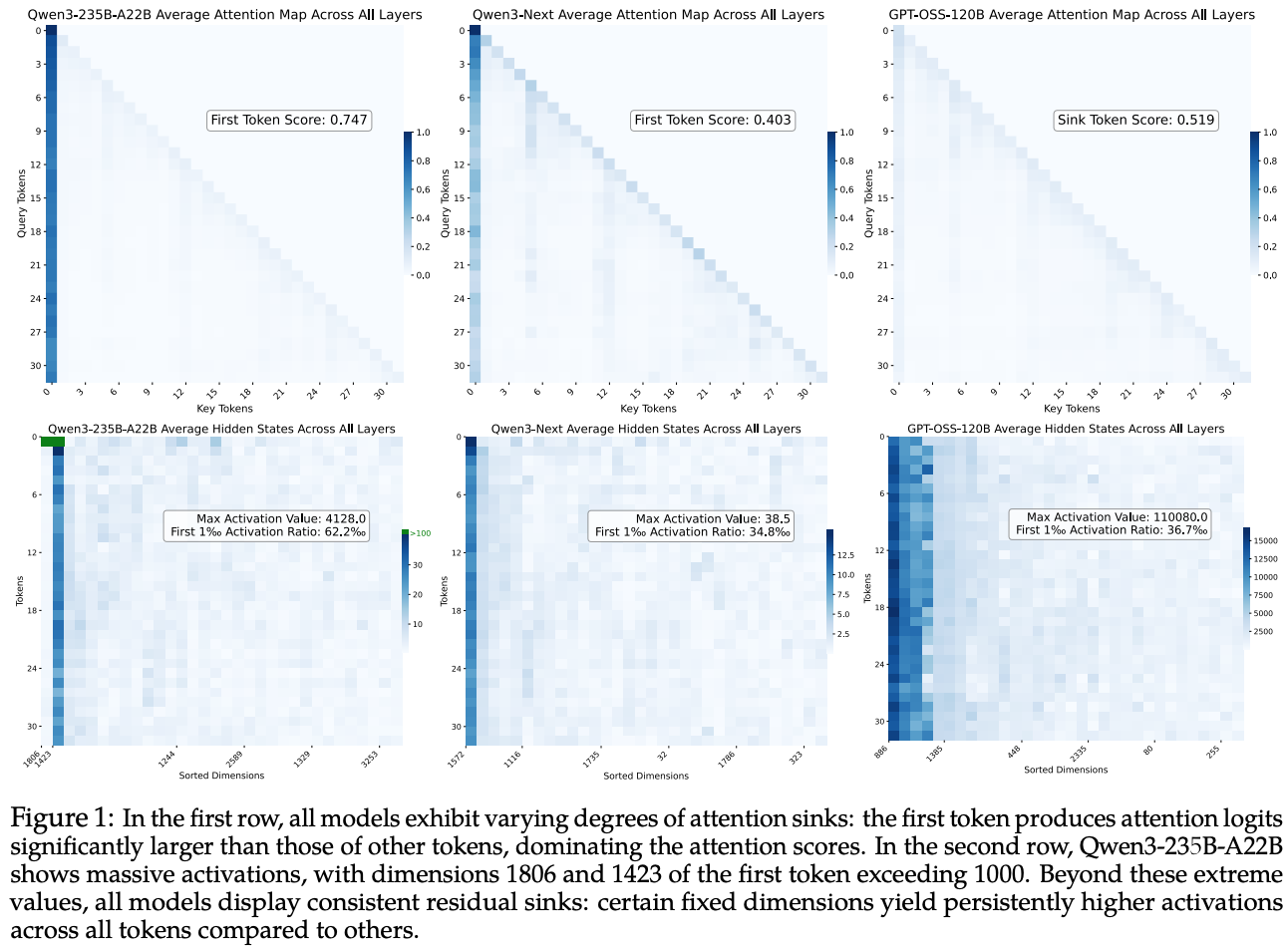
图1对Qwen3-235B-A22B、Qwen3-Next、GPT-OSS、以及 DeepSeek-V3分析outlier 模式的模型,
对每个模型,我们使用同一组输入序列,记录所有层的 attention maps 与 residual activations。在图 1 中,为清晰起见,我们对 attention maps 和 hidden states 在所有层上取平均。由于隐藏维度很大,直接可视化所有维度并不现实。为突出 outlier 模式,我们按整体激活幅度对特征维度重新排序。具体地,对每个维度,我们计算其在所有 token、层与输入上的平均绝对激活:
其中呢是层个token在维的激活,是Token总数。随后对降序。
观察主要包括:
- Qwen3-235B-A22B 中,几乎所有其他 token 都会持续对第一个 token 赋予很高的 attention 分数,呈现 attention sink。对应地,该 token 在两个维度上呈现 MA(例如维度 1806 与 1423)。除了 token 特定的 MA,我们还观察到:多数 token 在维度 1423 上都呈现持续较大激活。该模式跨输入稳定,在线性可视化中表现为一条深色竖条,其形状类似 attention sinks。我们随后发现,其在 normalization 过程中的 rescaling 效果与 attention sink 高度相似,因此称之为 residual sink。Deepseek-V3 也观察到类似模式:attention sinks、MA、residual sinks 同时存在。
- Qwen3-Next 在 attention 中引入 gating 以执行 gating-based rescaling,从而减少对 attention logit outlier 的依赖。因此其 attention sinks 相对更弱。 此外,其 residual stream 的最大激活幅度仅为 38.5,且未观察到明显 MA。尽管如此,维度 1572 仍在 token 之间持续呈现高于其他所有维度的激活,清晰体现 residual sink。
- GPT-OSS 引入 learnable sinks,从而有效将 attention sinks 从真实输入 token 上移除。MA 也随之消失 :真实 token 的 hidden states 不再在某些维度上出现极端值。这与先前解释一致:attention sinks 在 softmax attention 中扮演输入无关 bias;MA 通过 normalization 产生近 one-hot 向量,从而在投影到 key 空间时仅激活少数固定矩阵列。当显式提供 learnable bias(例如专用的 sink key)时,模型不再需要从真实 token 生成 MA。然而,尽管 attention sinks 与 MA 都不再出现,GPT-OSS 中 residual sinks 仍然存在。
3. Outlier-Driven Rescaling
实验Setup:2B参数、120B Tokens,如果影响了参数量就调整FFN层、保证总体参数量不变。
分析包括:
- 用 Dynamic Tanh等 point-wise 函数替换 normalization 能显著减少 outlier;但由于 DyT 无法提供 outlier-driven rescaling,训练稳定性与最终性能都会下降。
- 即便保留 normalization,直接通过 activation clipping 约束 outlier 也会破坏 outlier-driven rescaling,损害性能,甚至导致训练发散。这也解释了为何通过架构变化抑制 outlier 生成(如使用 sigmoid-based GLU)的方案往往表现较差。
- outlier 可无损地从激活转移到可学习参数中:在 normalization 前引入轻量可学习向量,模型仍可执行 outlier-driven rescaling,而无需在 residual stream 中显式产生大值,而是利用可学习向量后的放大投影。
- 通过 gating 显式提供 rescaling,可减少 residual sinks 且不造成性能下降。
- 引入 gating-based rescaling 后,模型对 outlier 的依赖降低,从而对架构选择的敏感性下降。具体而言,DyT 能稳定收敛,sigmoid-based GLU 在性能上可追平甚至超过 SwiGLU。
3.1. Removing Normalizations Reduces Outliers with Degraded Stability and Performance
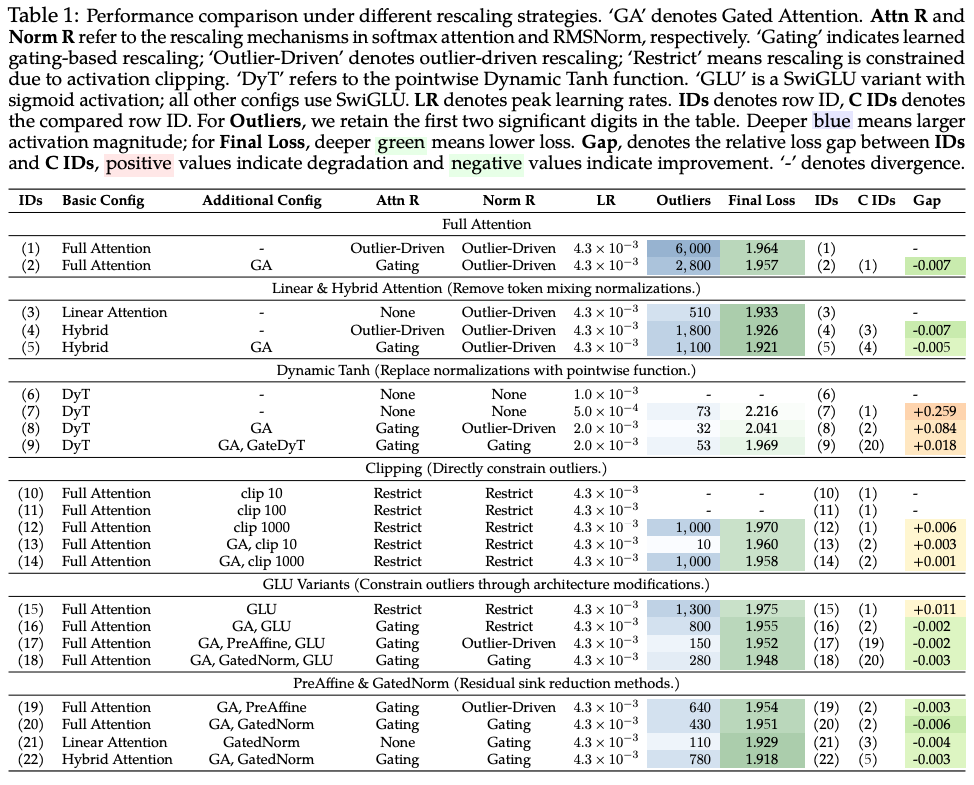
我们的实验发现:将 softmax-based attention 替换为 linear attention(即在 token-mixing 步骤中不做 normalization)也会减少 MA。如表 1 的第 (3)–(5) 行所示,linear attention 模型的峰值激活降至 510,而 full+linear 的 1:3 hybrid 模型峰值激活为 1100;相比之下,full attention baseline 为 6000。值得注意的是,虽然 linear attention 消除了 MA,但 residual sinks 仍然存在。 对包含DyT的所有设置做超参扫描,学习率取值集合并报告最优配置。最终仅在上收敛,Activation最大值将地位73,但是performance下降。这表明 outlier-driven rescaling 对训练稳定性与最终性能都至关重要。
综合来看,这些结果表明:移除 normalizatio(不管在Attention中还是Attention之外) 会破坏 outlier-driven rescaling 机制。结果是模型不再生成 outlier,但通常以训练稳定性与性能下降为代价。
3.2. Directly Clipping or Constraining Outliers Hurts Stability and Performance
现在考察,在保留normalization的情况下直接抑制outlier,考虑两种setup:
- 同时存在 attention sinks、MA、residual sinks 的模型;
- 通过 Gated Attention减少 attention sinks 与 MA、主要只剩 residual sinks 的模型。
首先,我们对 full attention baseline(表 1 第 (1) 行)的 residual 施加 activation clipping:将高于阈值的激活截断为该阈值。当阈值为 100 或更低时,训练早期即发散;当阈值为 1000 时,loss 曲线出现频繁尖峰,并收敛到更高的最终 loss(+0.006,第 (12) 行)。这与既有观察一致:在训练完成后对模型进行 MA 或 attention sink clipping 会严重损害性能,常常产生近随机输出。 其次,我们将 GA(减少 attention sinks 与 MA)与 residual clipping 结合。我们发现:一旦在 softmax attention 中通过 GA 重新引入显式 rescaling,即便非常激进的 clipping(阈值 10)也能收敛,但仍会损害性能(+0.003,第 (13) 行)。此外,在相同设置下,阈值 1000 的 clipping 只造成更小性能损失(+0.001,第 (14) 行)。
这暗示:
- attention 中的 outlier-driven rescaling 机制是被破坏时导致不稳定的主要来源;
- residual sinks 也对性能有重要贡献,若不提供补偿而直接约束它们,会导致退化。
除了Clipping外,修改activation函数也能更加温和地限制outlier。考虑SwiGLU:
outlier出现在上,然后被进一步放大。如果将swish替换为sigmoid,就能自然约束FFN的输出幅度。
表 1 显示:GLU 在收敛时的 outlier 幅度显著小于 SwiGLU(1300 vs. 6000),但性能下降 +0.011。这与已有发现一致:使用 sigmoid 的 GLU 往往不如使用 swish 或 GELU 的变体。在第 3.5 节中我们进一步观察到:当通过 gating 等显式 rescaling 降低对 outlier-driven rescaling 的依赖后,GLU 甚至能略优于 SwiGLU。
3.3. Fusing Outliers into Parameters
前述章节表明:outlier 在 normalization 中具有功能作用,若不做补偿就移除它们会损害性能。
从理论上,我们证明:在满足某些条件时,RMSNorm 后特征范数的上界会随 outlier 增大而降低,从而使 outlier 能 rescale 特征范数。现在我们提出问题:能否在减少显式 outlier 的同时保留其功能?
既有工作表明,learnable sink token 可以将 attention sinks 从输入 logits 转移到固定参数中,从而在保留 outlier-driven rescaling 的同时把 outlier 从真实 token 上移除。受此启发,我们在 RMSNorm 前引入一个可学习的逐元素 scale 向量(称为 PreAffine ):
其中是一个可学习的向量。由于 residual sinks 在几乎所有 token 上都稳定出现在相同维度,可以学习放大这些特定维度。这样,即便输入激活本身不含 outlier,经后仍可在选定维度产生大值,从而照常实现 outlier-driven rescaling。
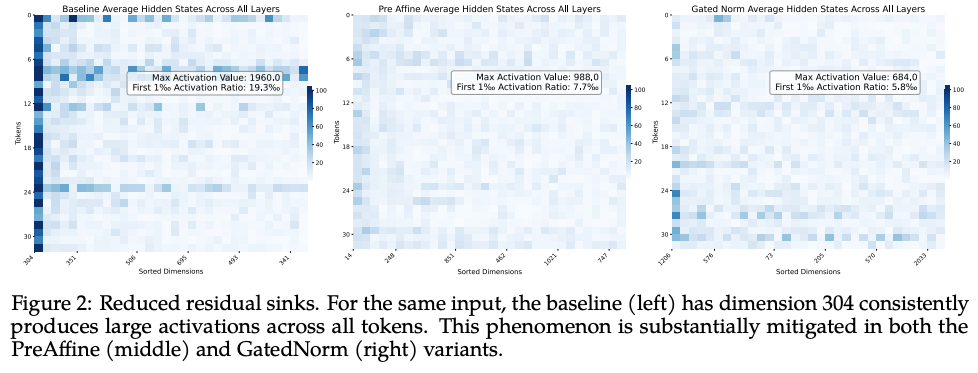
加入 PreAffine 后,网络最大激活从 2800 降至 640,且最终 loss 略有改善(-0.003,表 1 第 (19) 行)。我们也在一个 24.6B-A1.7B 的 hybrid MoE 模型上评估多种 outlier 缓解方法(配置见第 4 节),并在图 2 给出相应激活统计。左图为 baseline(使用 GA 抑制 MA):其中维度 304 在所有维度中持续具有更高激活,表明 residual sink;中图为同模型应用 PreAffine:任何单一维度的持续高激活消失,峰值激活从 1960 降至 988。
关键在于, 的 rescaling 能力不同于标准 RMSNorm 参数 。 会与 RMSNorm 发生交互:当 在少数维度取较大值时,它可以改变缩放后输入的 RMS,从而对非 outlier 维度的强度进行 rescale。我们在多个模型中分析了参数 (RMSNorm 标准权重)与 (PreAffine),完整结果见附录 A.5.1。我们聚焦于与 1 偏离最大的维度,因为这些仿射参数对表示的影响最强。观察如下:
- 在 baseline 中, 的绝大多数维度接近 1,但维度 304 在所有层中稳定偏离 1,最小可达 0.004。值得注意的是,baseline 的 residual sink 也出现在维度 304。这表明:residual sink 造成的大激活在 normalization 后会被迅速缩小。换言之,一旦某维度完成 outlier-driven rescaling 的角色,其下游影响会被刻意抑制。这与“attention sink token 的 value 向量范数更小”的观察相呼应。
- 在使用 PreAffine 的模型中, 偏离 1 的程度显著大于 。例如,在维度 1326 上 达到 7.19,而同维度的 仅为 0.06。这进一步支持:outlier 被用于通过 normalization 塑造表示,而其直接贡献会被压制。
3.4. GatedNorm: Explicitly Enabling Rescaling
的添加不能阻止normalization内部计算出现的outlier。借鉴GatedAttention,提出GatedNorm:
GatedNorm 仅增加 3.7M 参数,约为 2B 模型总参数的 2%。为保持参数量一致,我们略微减少 FFN 容量。在 2B dense 模型中,GatedNorm 带来约 5% 延迟开销;随着模型规模增大(尤其在 MoE 中)该开销进一步下降。
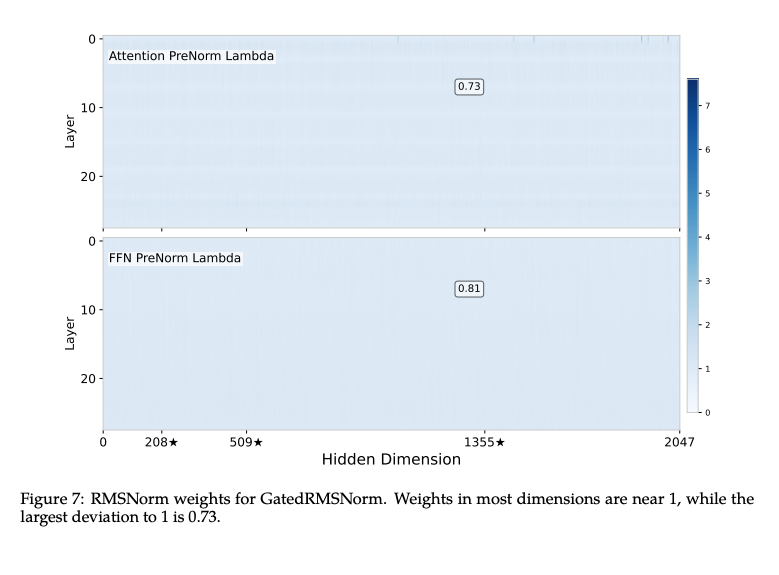
图 2(右)显示,在 24.6B-A1.7B 的 hybrid MoE 模型上,GatedNorm 同样能抑制 residual sinks。我们分析了使用 GatedNorm 模型中的: 偏离 1 的最大幅度仅为 0.73,而 baseline 中可到 0.004、PreAffine 模型中为 0.06。这表明:当网络不再依赖 outlier-driven rescaling 时,normalization 后对某一特定维度进行强抑制的需求消失;因此 normalization 输出更平滑,也更利于量化。
我们还比较了不同 gating 变体,重点考察两类设计选择:gating 粒度(逐元素,score 形状为,vs. 张量级,score 形状为 1)与激活函数(sigmoid、tanh、silu、identity)。结论如下:
- 逐元素 gating + sigmoid 激活能带来相对于 baseline 最显著的性能提升。张量级 gating + sigmoid 虽能在减少 residual sinks 方面与逐元素接近(支持 outlier-driven rescaling 假设),但最终性能接近 baseline,且稳定劣于逐元素版本。这表明:尽管两种粒度都能缓解 outlier,但更细粒度(逐元素)的 rescaling 能更有效调制,从而带来更好性能。
- 在逐元素 gating 下,将 sigmoid 替换为 tanh、SiLU 或不使用激活(类似 DiT 中的 adaLN)会导致训练过程中 outlier 动态不稳定。这暗示 sigmoid 的有界性及其在接近 0 区域的细粒度控制有助于稳定 rescaling,与 Chen et al. (2025) 的结论一致。更进一步,在张量级 gating 下,所有非 sigmoid 激活(tanh、SiLU、或无激活)都会导致训练发散,更凸显了使用行为良好且有界的激活(如 sigmoid)对稳定 gating 的必要性。
3.5 GatedNorm Improve Robustness to Architecture Choice
第 3.1 与第 3.2 节显示:DyT 与 sigmoid-based GLU 都不如 baseline。一个可能解释是:它们的架构内在地限制了 outlier-driven rescaling 机制。本节我们研究:是否能通过 GatedNorm 显式提供 rescaling,从而降低对 outlier 的依赖并恢复性能。
我们首先为 DyT 配置 GA(表 1 第 (8) 行),以在 attention 模块中提供显式 rescaling。这使模型能够在 baseline 的学习率(4.3e-3)下稳定训练,尽管其最优学习率为 2e-3。这进一步确认 attention rescaling 对训练稳定性的关键作用。随后我们在 DyT 层之后加入一个低秩 self-gating 机制,类似于 GatedNorm,得到 GatedDyT(表 1 第 (9) 行)。加入后,DyT 与 RMSNorm baseline 的性能差距从 0.084 缩小到 0.018,凸显显式 rescaling 不仅在 attention 中重要,在 normalization 层本身也同样关键。
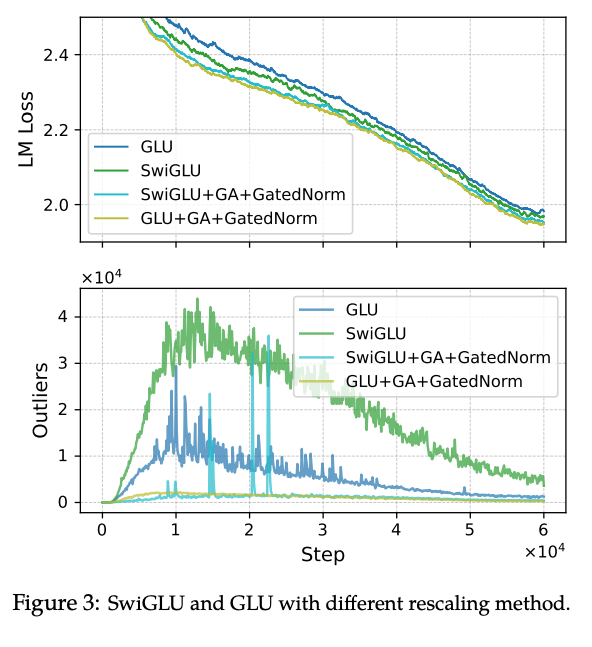
我们进一步比较 SwiGLU 与 GLU 在引入/不引入 GatedNorm 时的差异。如图 3(下)所示,原始 SwiGLU 在训练中产生的最大激活超过,而原始 GLU 的峰值约为。由于缺乏 outlier-driven rescaling,GLU 收敛到更高的 loss(+0.011)。在使用 GatedNorm 后,在同一设置下 GLU 略优于 SwiGLU(表 1 第 (16) 行为 -0.002;第 (17) 行为 -0.003)。图 3(上)显示:引入 gating 后,GLU 的 loss 曲线从所有变体中最差(蓝色)变为最好(绿色)。
这表明 GLU 与 SwiGLU 的性能差距主要源于它们在支持 outlier-driven rescaling 方面能力不同。这也解释了为何更容易产生 outlier 的高阶激活函数(例如 ReLU2或 PolyNorm)在需要这种 rescaling 时可能更有优势。当通过 GatedNorm 显式提供 rescaling 后,模型对那些会影响 outlier 生成的架构选择变得更鲁棒。
4. Scaling Outlier Mitigations and Deployment-Level Quantization
在本节中,我们在大规模设置下评估 GatedAttention 与 ** GatedNorm** 的不同组合,以及 ** PreAffine**。如表 1 第 (5) 行所示,hybrid 模型具有优势。因此,我们参考 Qwen3-Next 的设计,在高效的 hybrid MoE 模型上开展实验,包含两种设置:
(1) 参数规模 7.4B、激活参数 1.7B 的模型(MoE-7B-A2B),训练 1.2T tokens;
(2) 参数规模 24.6B、激活参数 2.7B 的模型(MoE-24B-A3B),训练 500B tokens。
在该设置下,GatedNorm 带来的 latency overhead 小于 3%。
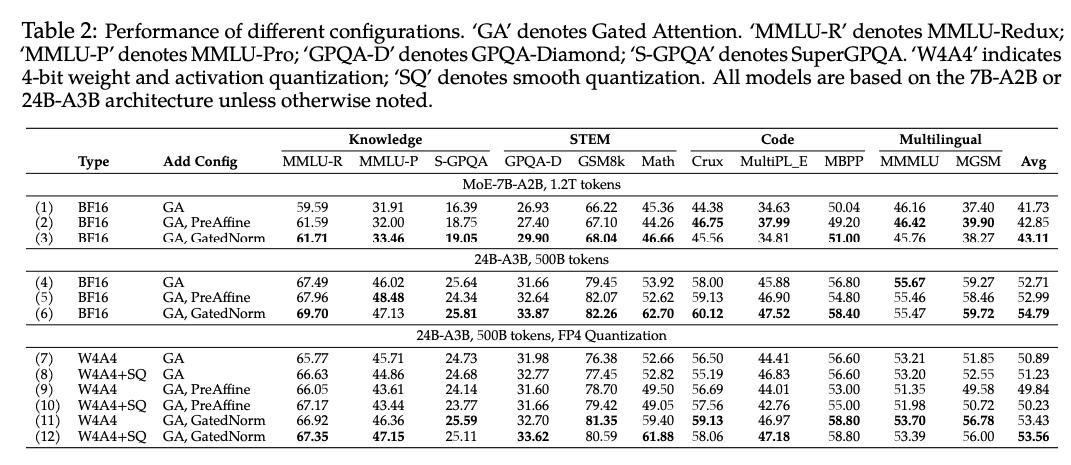
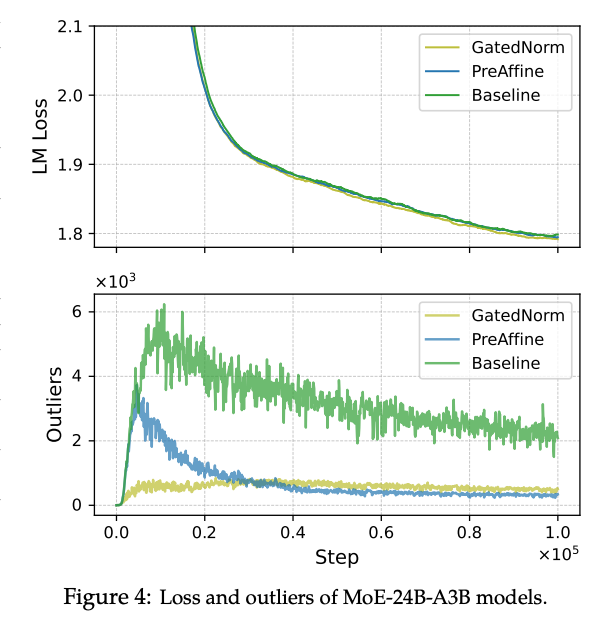
图 4 展示了 MoE-24B-A3B 模型的训练 loss 曲线与 outlier 变化。我们的观察如下:
- Baseline 的 outlier 在训练早期迅速上升,并随着学习率下降逐渐衰减。PreAffine 模型同样在训练初期出现 outlier 激增(约发生在训练前 10% 内),但随后迅速减弱。一种可能的解释是:可学习的 scaler在初期尚不足以提供支撑 outlier-driven rescaling 所需的幅度,因此模型会暂时依赖激活 outlier。随着训练推进,的特定维度逐渐变得足够大,outlier 因而被“吸收”进参数之中。相比之下,GatedNorm 在早期没有 outlier 激增,并在整个训练过程中维持较低且更稳定的激活幅度,表明其对 outlier-driven rescaling 的依赖更低。
- 在训练中后期出现了清晰的性能差距:GatedNorm 达到了更低的最终 loss。
在 FP4 量化下,我们观察到:
- 对仅使用 GA 与 PreAffine 的模型,SmoothQuant平均带来约 +0.5 分增益,且该增益高于其对 GatedNorm 的增益。这暗示 GatedNorm 的 rescaling 在很大程度上缓解了模型对 outlier 的敏感性。
- GatedNorm 在 FP4 量化后的性能下降最小(-1.23 分);相比之下,GA 为 -1.50,PreAffine 为 -2.76。在 MGSM 基准上,只有 GatedNorm 能将退化控制在 5 分以内,其他方法几乎都出现接近 10 分的损失。
这种更强的量化鲁棒性与我们对 gating-based rescaling 的一项观察一致:它具有 outlier-suppressing 行为——当某些维度的 较大时,往往会得到更小的 gating 分数 ,从而使最终激活更平滑。总体而言,PreAffine 将 outlier 进行“搬迁”,其思想与 learnable sink 和 SmoothQuant相近,但仍依赖 outlier 来完成 outlier-driven rescaling;相对地,GatedNorm 通过显式 gating 使网络整体产生更平滑的激活,并获得更优的量化鲁棒性。
5. Related Works
Transformer 中的 outlier 现象已被广泛研究。在 BERT 模型中,固定维度上的 outlier 主要归因于 LayerNorm 的 weight 与 bias 参数,并与特殊 token 的 attention 模式密切相关这一现象与 GPT 风格模型中的 attention sink 类似,并会显著影响模型性能。BERT 中讨论的 outlier 在自回归模型中大体对应 MA 。这些 MA 通常起源于语义稀疏的特殊 token,在 FFN 中较早出现,并沿 residual stream 传播,持续影响后续层的 attention 分布。
一些工作识别出 GPT 模型中输入无关、持续出现在固定维度上的 outlier。这些 outlier 与 attention sinks 并无直接关联。He et al. 进一步将这些 outlier 归因于 normalization 本身,并展示即便移除 LayerNorm 权重,它们仍会存在。由于 outlier 会同时损害训练与推理阶段的量化效果,已有大量方法试图缓解其影响。常见技术包括:采用按行、按通道、按组的 scaling 以限制 outlier 引起的量化误差,以及使用 Hadamard 变换在不同维度间重新分配 outlier。
另一些研究关注在训练过程中减少 outlier。从优化角度,诸如增大 weight decay、gradient clipping、约束权重方差,或加入显式的正则化 loss 项等策略都可以抑制 outlier。一些研究也考察 Adam 优化器是否会在预训练阶段导致 outlier。从架构角度,已有工作注意到 outlier 与 normalization 之间存在强关联,并提出通过移除 normalization 来消除 outlier。我们的工作表明:通过架构干预、显式替换 outlier-driven rescaling,模型在仍使用 Adam、标准训练配方与 normalizations 的前提下,也能够在显著更小的激活幅度下完成训练。
与我们最相关的是那些研究 outlier 功能角色的工作。Bondarenko et al. (2023) 与 An et al. (2025) 提出 attention outlier 充当上下文相关的 scaling 因子,并证明在 attention 中引入 gating-based scaling 能减少 attention outlier。Karras et al. (2020) 在 StyleGAN 的中间特征图中识别出 normalization 是 outlier 的来源,并指出这些 outlier 用于在 normalization 过程中对信号进行 scale;进一步地,该工作显示:即便没有 normalization,通过 gating 生成的输入依赖卷积权重也能复现这种 scaling 效果。这种 gating-based scaling 也被 adaLN采用。我们的工作将这一洞见扩展到 LLM 中的 residual sinks,强调 outlier-driven rescaling 在 Transformer 中的广泛存在,并通过一系列有针对性的架构干预提供了系统性证据。
6. Conclusion
本文认为,LLM 中的 outlier 并非仅是伪影,而是具有功能角色。它们与 normalization 机制(softmax 与 RMSNorm)协同工作以执行 outlier-driven rescaling ,从而对非 outlier 特征的幅度进行 rescale。该机制对稳定训练与强性能至关重要:移除 outlier 并破坏 outlier-driven rescaling 会损害模型。通过显式提供 gating-based rescaling,我们可以在减少激活 outlier 的同时保持甚至提升性能。此外,显式启用 rescaling 会降低对架构选择的敏感性。这些方法也会产生更平滑的激活,并显著提升量化鲁棒性,尤其是在激进的低比特设置下。