最近为了评估AsyncT的模型性能,需要跑各种越来越大越来越复杂的Benchmark。之前是直接在Megatron里起一个step=final的训练脚本,用最后一次保存ckpt时候触发的lm-eval跑结果。但整个流程速度极慢,单独跑一个gsm8k就需要将近40分钟,效率太低了。加之最近正在思考这个显然更简单的新结构在GPU上能取得哪些现阶段就能够claim的优势,遂做此结构的推理框架适配和优化。
0. Preliminary
相比于Softmax Transformer,AsyncT主要的不同在于:
- 将Transformer中所有的RMSNorm(pre-norm,qk-norm,final norm,以及下文提到的Peri-LN启发的post-attn norm)替换为DyHT:
是参考何恺明Transformer without Normalization中DyT的SNN & Quantization更友好的版本。他的论文中其实就提到过DyT有理论上比RMSNorm更高的计算效率(访存显著减少,并且element-wise操作更好fuse),不过原论文中的实验做的比较naive,知乎上也有人攻击1。
- 将Softmax Attention替换为:
相比于Softmax,主要区别在于(1)将其中的Softmax算子移除替换为了AsyncI,进一步移除了模型中的normalization;(2)由于移除normalization后Attention Score之和为1的约束一同消失,将Softmax中原本为的scaling factor修改为。
- 在Attention之后、Residual之前添加了一个额外的DyHT,用于稳定模型输出。此方法的启发来源于Peri-LN,没有像原文一样在MLP之后也添加是因为测试出来效果不算很好。
- 将FFN中的SwiGLU替换为ReGLU,主要区别是将其中的SiLU替换为了ReLU。一开始的目的是为了避免构造差分形式的SNN算子,不过后面ReLU Strikes Back和Sparsing Law等论文指出,使用ReGLU在常见的Benchmark上并不会引入特别多的perf degradation,同时还有稀疏度更高、硬件更友好(不用SFU了)等优势性质。
通过以上算子的修改,AsyncT相比于Softmax(可能,或者说我们希望)具有以下优点:
- LoCC Friendly,算子完全适配我们在ViStream中提出的LoCC Law,移除normalization之类的synchronous算子之后模型能够非常流畅地转换为能够在异步硬件上部署的SNN;
- Quantization Friendly,之前分享的A Unified View of Attention and Residual Sinks: Outlier-Driven Rescaling is Essential for Transformer Training指出,LLM中的outlier往往是由于模型尝试利用softmax/rmsnorm中的normalization进行rescaling产生的,而我们不仅移除了normalization,还通过DyHT强硬地限制了每个元素位置上输出的数值范围,保证了模型的稳定性,理想情况下量化也会非常容易;
- Sparse Friendly,这个friendly的叫法有点强行,不过将SwiGLU替换为ReGLU确实观察到了模型的稀疏性显著提高的情况,下面这个模型在训练中就已经发现了MLP中~70%的平均稀疏度,并且按Sparsing Law的描述模型继续训练会变得更加稀疏。
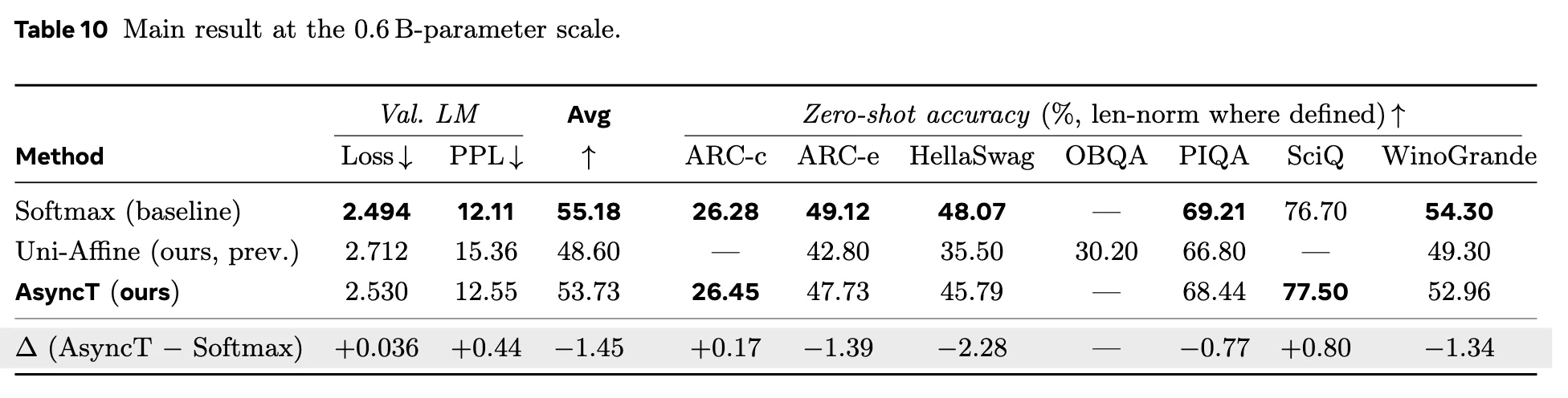
可以看到总体而言AsyncT相比于Softmax Model的差别还是非常大的,比较意外地是这个模型在我们的setup下观察到了可以说是接近Softmax Attention Model的能力表现,还是比较惊喜的。那接下来的重点就是如何将上面这个模型嵌入到vllm中,vllm中这么多成熟的technique有多少能在AsyncT上直接应用就能得到收益,而有哪些是为了softmax model设计的在AsyncT上需要修改、反而可以利用AsyncT自己的性质来减少麻烦等等。
1. VLLM适配
1.1. PyTorch基本版
要做适配当然要从一个最基本的PyTorch版本开始,起码测一测保证里面该换的东西都能换,之后也有一个精度Baseline和一个优化的对比。好在VLLM已经是个成熟的大框架,支持的各种Backend本来就非常多,要做这个适配基本上核心工作量都在写AttentionMetadataBuilder(每步把 block table、seq lens 等元信息打包)和AttentionImpl.forward(拿到 Q/K/V 和 metadata,写出 attention output),其他部分还是些小修小改。
具体而言,我们需要实现的内容包括:
AttentionBackend:静态描述类,告诉引擎 KV cache 的形状、dtype,以及对应的Impl/Metadata/MetadataBuilder类。AttentionMetadata:每个 forward step 里描述”这一步有哪些 request、各自的 Q range、KV seq_len、block_table”的不可变结构体。AttentionMetadataBuilder.build():在 forward 之前把上面的 metadata 从 scheduler 状态构造出来。这一步在 CUDA graph capture 之外 ,是允许做.tolist()/ Python 控制流的最后一个安全窗口。早期很多性能问题,本质上就是在每层 forward 里重复做了本该 build 一次的事情。AttentionImpl.forward(layer, q, k, v, kv_cache, attn_metadata, output, ...):每一层 attention 都会调到这里。注意 vLLM 在一次 forward 里会把同一个 attn_metadata 对象 传给所有 35 层 attention:很多 decode indices、fake prefill seq_lens、block table 切片都可以挂到这个 metadata 上,只构造一次,然后 35 层复用。
KV cache 的 layout 先直接对齐 FlashAttention:[2, num_blocks, block_size, num_kv_heads, head_size](第 0 维是 K/V)。这个选择有两个理由:
reshape_and_cache_flash这个 op 已经在_C里编译好了,写 KV 直接拿来用就行;- 后面想偷 FA 的某些工具(比如
flash_attn varlen prefill的 cache 路径)会更容易。
代价是访存模式不如 vLLM 自家的 paged_attention_v2那种 head-major + interleaved-x(差大概 10-20%),不过这只是作为baseline的一个基本实现,所以无关紧要。
for req in requests:
gather K/V
build mask
hp1_attention_eager()
scatter output这个纯PyTorch实现跑gsm8k要2131秒,HF eager只要771秒——vLLM比HF慢了2.76倍。vLLM 的强项是把大量 request 的 decode/prefill 合并成连续 GPU workload;而这个版本等于把 vLLM 的 batch 又拆回了 Python request loop。profile结果指出:vLLM每个forward step会有约250个并发request × 35层attention = 约9000次Python迭代。AttentionImpl.forward本身就在Python端做per-request的block_table[req_idx, :num_blocks]、k_flat[tok_indices]、调用hp1_attention_eager_kv(...)、output[q_start:q_end] = ...这一连串操作。每一步都在GPU上launch小kernel然后等host侧Python决策,整个pipeline完全是launch-overhead-bound的。
所以后面这一轮优化的主线就变成:把 request 维度从 Python loop 里拿出来,变成 batched tensor / GPU kernel / graph replay 的一部分。
1.2. Batched Padded Matmul
既然per-request Python loop是bottleneck,就把所有request合并成一个padded batch做一次性的matmul:
# 先扫一遍算出最大长度
for req_idx in range(num_reqs):
max_t_q = max(max_t_q, t_q)
max_t_kv = max(max_t_kv, t_kv)
# 分配padded tensor
Q_padded = torch.zeros(B, max_t_q, H, D, ...)
K_padded = torch.zeros(B, max_t_kv, Hkv, D, ...)
# 用memcpy-only的Python loop填充(无per-request matmul)
for b, (req_idx, q_start, t_q, t_kv) in enumerate(req_info):
Q_padded[b, :t_q] = query[q_start:q_start+t_q]
# 关键:tok_indices一次构造,然后k_flat[tok_indices]做gather
K_padded[b, :t_kv] = k_flat[tok_indices]
# 一次batched call
Out_padded = asynct_attention_eager(Q_padded, K_padded, V_padded, ...)注意这里有个微妙之处:Python loop还在,但loop体里没有任何matmul 。loop只做Q_padded[b, :t_q] = query[q_start:q_start+t_q]这种memcpy。matmul被推到了hp1_attention_eager(...)这一次batched call。
通过上面这个简单的batch做法,arc_easy加速了2.21倍,但gsm8k OOM了——256个请求 × 2048 max_t_kv× 4个KV head × 128维 × 2字节 × 35层 = 数GB级别的padded K/V tensor。所以接下来要做长度分桶。
1.3. Length Bucketed Batching
核心idea是按t_kv排序,然后greedy地把request塞进chunk,确保每个chunk的B_chunk * chunk_max_t_kv不超过预算(131072 tokens):
sorted_by_kv = sorted(range(len(req_info)), key=lambda i: req_info[i][3])
for i in sorted_by_kv:
new_max = max(cur_max_tkv, t_kv_i)
if (len(cur) + 1) * new_max > BUDGET_TOKENS:
chunks.append(cur)
cur = [i]这样改完还有个好处:短request聚在一起时,它们所在chunk的max_t_kv也很小,padding浪费骤减。gsm8k从2131s降到928s,同时也修了OOM。HF eager的差距从2.76×缩到1.20×。
但这里仍然有两个问题:
- 每个 chunk 内仍然要准备 padded tensor;
- 每个 request 的 K/V gather 仍然是在 Python loop 中一个一个做。
1.4. Vectorized Gather
可以看到上一轮代码里loop中还有一些index-only的操作,那可以把它们也vectorize。把 block table 展开成 [B_c, chunk_max_t_kv]的 token index 矩阵:
tok_indices =
block_table_chunk.view(B_c, max_blocks, 1) * block_size
+ offsets.view(1, 1, block_size)然后一次性:
K_gathered = k_flat[tok_indices]
V_gathered = v_flat[tok_indices]Q 也用类似方式 gather。这样 Python loop 只剩少量 chunk 级逻辑,不再每个 request 发起独立 gather/matmul。结果 gsm8k 到 457s,比 HF eager 快 1.69x。
1.5. Python侧一些其他的尝试
前面提到decode indice是可以通过一次build给所有层复用的,但当前的代码每次做attention的时候都重复构建
q_decode_rows
seq_lens_dec
block_table_dec
kv_indptr
kv_indices
mid_o
filter_w等decode indices,因为 vLLM 一次 forward 中所有层共享同一个 attn_metadata,这些完全可以只构建一次,挂到 metadata 上。
之后又尝试启动CUDA Graph,结果反而整体反而变慢。可以看出在Kernel执行时长还是显著的瓶颈的时候,启动CUDA Graph不一定是个有意义的操作。之后在做CUDA Graph等的修改之前,一定要先profile、确认各种kernel launch的间隔相比于kernel本身执行的时间已经不可忽略了,再考虑这样的优化。
2. Triton Decode Kernel
PyTorch端很难融合FIR + clamp + p@V这串element-wise + reduce的混合op,开始快速把之前Megatron里的Triton Kernel搬进来,先从Decode开始。
2.1. Naive Two Stage Decode Triton Kernel
整个Triton path是两阶段kernel设计:
Stage 1:每个(req, q_head, split)组合一个program,在该split的K范围内:
- 加载Q [HEAD_SIZE]
- 构造banded-Toeplitz FIR matrix [BLOCK_N, BLOCK_N]——这里有个trick,HP1的因果FIR可以用Toeplitz矩阵的
tl.dot表达 - 按BLOCK_N tile扫K:
s = q · K^T → relu → tl.dot(·, FIR_toeplitz) → lp_scale → s_hp → clamp gate → p · V - 写到
Mid_O_ptr[req, q_head, split_id, head_size]
Stage 2:sum reduce各个split的partial output。因为p(HP1的gate输出)和V的乘积是线性的,各split的partial output直接相加即可,不需要像softmax那样追加exp scale matching。
@triton.jit
def _hp1_decode_stage1_kernel(
Q_ptr, # FULL query buffer [num_q_tokens, H, D]
Q_Rows_ptr, # [num_decode_reqs] int64 row in query for each decode req
...
):
cur_req = tl.program_id(0)
q_row = tl.load(Q_Rows_ptr + cur_req) # indirect indexing
q = tl.load(Q_ptr + q_row * stride_q_t + ...).to(tl.float32) * qk_scale
...
@triton.jit
def _hp1_decode_stage2_kernel(
Mid_O_ptr,
Out_ptr, # FULL output buffer
Q_Rows_ptr, # row in Out_ptr to write to
...
):
cur_req = tl.program_id(0)
out_row = tl.load(Q_Rows_ptr + cur_req)
# ... sum across splits, then store to Out_ptr[out_row, head, :]这里有个相对Triton原生不友好的部分:
lowpass[k] = avg(relu(score[k]), relu(score[k-1]), relu(score[k-2]))在 Triton 里最直接的写法是构造一个 banded Toeplitz 矩阵
然后用 tl.dot:
relu_scores [BLOCK_N] × Toeplitz[FIR_K] -> lowpass[BLOCK_N]这样做代码逻辑最简单,边界控制也方便。对于Kernel Size = 3的情况来说,上面的矩阵显然大部分位置都是0,用一个矩阵乘来实现shift-add的效率实在是太低了。然而,Triton 的寄存器 tensor 模型不太方便表达“从寄存器 tile 里按 k-i shift 取值”的直接 FIR,尤其还要处理 split 边界的 FIR_K-1left overlap。
2.2. 带宽优化
做简单profile,发现K/V Load是带宽的主要任务。两个比较直觉性的想法:
- 将所有的Q Head一起打包成
acc[H_q, HEAD_SIZE],在一个triton kernel执行过程中一次性做reduce,节省KV Cache的读取。结果效率反而大幅度降低;经检查是打包后register数量大幅度增加,导致反而溢出到local memory上; - 只在GQA Shared的head上共享KV Cache Load,但现在的模型结构只有GQA2,
K/V bandwidth saving = T_kv × Hkv × D × 2 bytes / 2 ≈ 14μs/layer at H200 4.8 TB/s peak,好像没啥用,遂放弃。
3. Naive CUDA Kernel
Triton Kernel的各种写法在之前MegatronLM上写训练算子的时候研究的已经很多了,限制还是太多了:
- Triton的register tensor没法做FIR的”register tail across tiles”,只能用左overlap regenerate
- Triton没有warp-level primitive,没法做cooperative QK dot
- 共享Q across head是pattern-level的,Triton没有CTA-shared smem的细粒度控制
再在Triton Level上研究各种尝试对现在这个Kernel的形态意义不大。
3.1. First CUDA Kernel
复用vLLM的paged_attention_v2_kernel模板:
- 直接读FA cache layout
[num_blocks, block_size, num_kv_heads, head_size] - Per-thread sequential K loop(朴素到不能再朴素,1 CTA per (req, head))
- 用shared memory做AvgPooling:
__shared__ float logits[MAX_SEQ_LEN + FIR_K - 1]; // 前面留Kenrel Size - 1个history slot
__shared__ float p_buf[MAX_SEQ_LEN];
for (int t = tid; t < seq_len; t += NUM_THREADS) {
const int idx = t + FIR_K - 1;
float fir_sum = 0.0f;
#pragma unroll
for (int k = 0; k < FIR_K; k++) {
float v = logits[idx - k]; // ← 直接在shared mem里下标访问,方便多了
if (hp_relu_pre) v = fmaxf(v, 0.0f);
fir_sum += v;
}
// ... gate compute ...
p_buf[t] = gamma_v * p_val;
}跑BS=32, T_kv=1024的Micro Bench相比于Triton版本立刻获得~20%的提速,效果明显。但gsm8k实际上下降6%(385s vs 362s)。原因:前面的dispatch只在num_prefills == 0时启动CUDA path(即pure decode),mixed batch全部fallback到Triton;而gsm8k因为continuous batching大量是mixed batch。
3.2. Mixed-batch Dispatch
把dispatch CUDA Kernel的条件,从num_prefills == 0改成num_decodes > 0。CUDA path处理mixed batch里的decode subset,Path B Triton/eager只处理prefill subset。
if (_cuda_enabled and attn_metadata.num_decodes > 0 and H * D == 1024):
num_decodes = int(attn_metadata.num_decodes)
torch.ops._C.hp1_decode_paged(
output[:num_decodes], query[:num_decodes],
key_cache, value_cache,
attn_metadata.block_table[:num_decodes].to(torch.int32),
...
)
if attn_metadata.num_prefills == 0:
return output # pure decode — fully done
# fall through to Path B for prefill subsetvLLM的scheduler把decode request和prefill request在同一个batch里排在一起(decode在前,prefill在后),所以output[:num_decodes]和query[:num_decodes]就刚好切到decode subset。
3.3. Kernel Fusion
既然已经开始写CUDA Kernel了,就给其他的如UClip、ReGLU等都写一下实现、控制一下kernel launch的情况:
template <typename scalar_t, int NUM_THREADS,
bool ALPHA_PER_CHANNEL, bool GAMMA_PER_CHANNEL>
__global__ void uclip_norm_kernel(...) {
for (int d = tid; d < hidden_size; d += NUM_THREADS) {
float xf = uclip::to_float(x_row[d]);
float a = ALPHA_PER_CHANNEL ? alpha[d] : alpha[0];
float g = GAMMA_PER_CHANNEL ? gamma[d] : gamma[0];
float v = fminf(fmaxf(a * xf, clip_min), clip_max) * g;
y_row[d] = uclip::from_float<scalar_t>(v);
}
}不过要注意:
- Q/K 来自 fused QKV projection 的
split,常常是 non-contiguous narrow view; - 简单要求
x.is_contiguous()会导致 Q/K norm 走 PyTorch fallback; - 直接
.contiguous()再调 fused kernel 会引入 copy,反而更慢; - stride-aware kernel 如果只用一个 row stride,不处理 3D
[N,H,D]的中间维 stride会算错结果;
最后的效果其实和PyTorch Eager版本差距也没有那么大。
ReGLU同理,用一个relu_and_mul替代relu(gate) * up两步。
做了Kernel Fusion整体的inference能力已经大幅度提升,此时端到端的性能已经基本赶上Flash Attention2的速度。
3.4. CUDA Graph Again
这时候很自然地想,既然之前是Kernel性能受限,现在Kernel性能应该没什么问题了,总可以用了?结果启动CUDA Graph后捕获成功,但总吞吐继续变慢,还没有仔细做Benchmarking,看来这边还有一些比较神秘的问题2。
至此Part 1的故事到一个阶段性节点:从per-request Python loop = 2131s走到CUDA decode + Triton fallback = 277,7.7× wall time减少,纯靠对vLLM架构(AttentionMetadataBuilder timing、KV cache layout、layer-level dispatch)的细致挖掘。
到这里,基本上算是实现了我们第一阶段的目标,此算子能够非常轻松地支持我们对各种Benchmark评估过程的支持、再也不用像之前一样等一两个小时跑一个小模型的eval结果、还需要大量占用卡的显存了。不过在优化的过程中我们实际上能够发现,AsyncT在算子优化领域上实际上具有非常大的优化潜力,这和它的无normalization(or async)的数学形态是息息相关的。下一节进入CUDA上的算子优化、Hopper架构特性的完整利用。
Footnotes
-
如何评价 Meta 新论文 Transformers without Normalization? - 寒月灼华的回答 - 知乎 https://www.zhihu.com/question/14925347536/answer/124311637540 ↩
-
不过后面会发现,这实际上是Benchmarking存在问题,其中的warmup做法不太干净,此处的graph mode实际上已经可以引入不少收益了。 ↩