这一段时间一直在做SNN GPU Framework的工作,计划是通过SNN的特殊性质实现在GPU上的加速,不过到最后也没做成。把之前试过的看过的方法都做个总结。
0. Intro & Preliminary
0.1. Quantization
现在各种做推理/训练加速的工作,最关注的内容基本可以归结到量化和稀疏两个话题上。考虑一个神经网络的推理,可以概括成:
量化就是将网络中的替换成更低精度(如,),从而
- 节省传输两者的带宽:单个元素占用的字节数缩小的情况下,同样的DRAM-L2-寄存器链路上就能在一个周期中搬运更多数量的元素,也让对应的参数能够更好地缓存在片上的SRAM/L2中,降低了Cache Miss的次数;
- 或是利用GPU的并行性质一次计算更多数量的元素:现代MMA/Tensor Core指令中在一条指令中一般处理固定bit-budget量的块,因此单个元素的位宽越小,在相同指令中就能并行处理更多元素(前提是硬件支持对应的位宽,并且accumulation和dequantization的开销不会“反噬”收益)。
但注意到,量化压缩的计算和传输由位宽决定,注定存在的上限,尤其是此处很有可能是一个离1较远的数。一系列(主要是LLM相关的)工作发现,将压缩到以下时,受到outlier的影响、FFN/Attention中大量累加在超低精度下的噪声影响,会出现非常严重的精度误差。因此,一系列工作又开始重新审视模型中的稀疏性。
0.2. Sparsity
稀疏性实际上并不是一个新鲜的话题。在机器学习非常早期的时候就已经有剪枝的工作了1。随着机器学习在现实中的不断应用,大家也开始关注在实际场景中的推理速度,剪枝算法关注的重点也慢慢从防止过拟合、提高泛化性,转向了降低模型的计算量、提高推理速度。
同样形式化地来说,稀疏性的网络推理可以写作:
其中中的0就是剪枝剪掉的元素,当(为稀疏度)的时候,同样也可以:
- 节省传输带宽,因为实际计算中只有非0值才会对结果做出贡献,因此只需要传输非0的数据进行计算,而为0的数据既不需要计算也不需要传输/存储;
- 同理也降低了计算量。
根据稀疏的模式(结构化的?非结构化的?)、稀疏的对象(权重?激活?或者两者都有?)、稀疏性产生的时机(稀疏性是在运行前决定的还是运行时产生的?),又可以将稀疏进一步细化、分类。
0.2.1. Structured vs. Unstructured, Sparse Encoding
非结构化稀疏是指,稀疏矩阵中0的位置完全自由,没有任何约束。非结构化稀疏可以说是稀疏最自然的一种模式,如ReLU等激活函数产生的稀疏性。但直接存在的非结构化稀疏,在GPU上的利用相当困难(产生非连续访存、Warp Divergence等各种问题)。因此,采用了非结构化剪枝的工作,往往需要引入稀疏编码。
常见的稀疏编码包括:
- COO,存储的是
<row idx, col idx, val>三元组,结构最直观,但是两个维度的索引占用4B,极大程度地增大了传输数据时的带宽开销; - CSR/CSC,存储的是
values, col idx, 行/列指针ptr,让同一行/列中的非0元素相邻存放,便于GPU在计算的过程中,让一个warp内的thread可以直接连续地取数据 - ELL/ELLPACK,为每一行预留
k_max个内容槽位,存储val[k], col[k],这样存的优点是内存仍然保持了一个比较规整的2D布局,可以直接按照(row, k)映射到(warp, lane)上,进一步降低访存开销 - HYB,主干用ELL,溢出的行用COO,早期NVIDIA的SpMV Kernel中的数据编码就是这么做的
可以看到,不管是什么样的稀疏编码,总是还有一些额外的维护稀疏数据结构的开销。同时,如果想要将一个稠密的矩阵转换为一个稀疏编码的矩阵,总是至少需要遍历一遍完整的稠密矩阵,开销就更大了。另一方面,cuSPARSE这样的库中设计的算子,一般计算都是Sparse * Dense = Dense的,这意味着如果我们需要将稠密的输出值转换为下一层的稀疏输入,就不可避免地会遇到上面的巨大编码开销。
而在结构化稀疏中,稀疏按照一种预先设计好的结构(如上三角,按channel,按block等等)分布。结构化稀疏往往是为了更好地利用硬件的某种计算特性(从而设计比较好的计算pipeline),如Block-CSR的做法,按的小块做稀疏性维护,这样索引相对元素的数量也减少了,同时每个小块的运算还可以直接映射到Tensor Core上,进一步降低了稀疏性利用的开销。
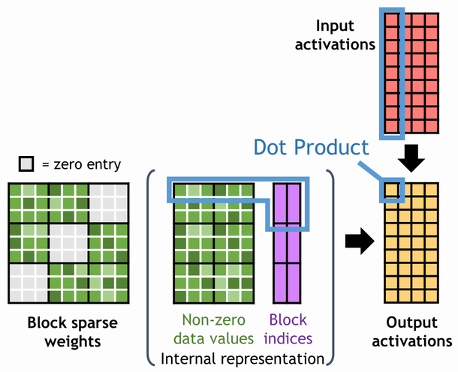
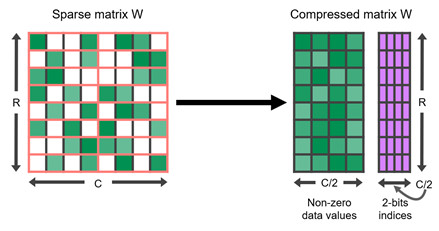
NVIDIA在Ampere架构开始,引入了一种Sparse Tensor Core2,支持计算2:4稀疏。2:4稀疏的模式如下图所示,基本可以概括为一个的小块中,保证至少有两个0。Sparse Tensor Core做了对应的硬件加速。在Hopper架构中还有实验性的V:N:M稀疏,思路也是类似的。
结构化稀疏在硬件上更友好了,但代价是需要在训练阶段引入一些额外的约束,一方面是这种约束会对网络的精度产生影响,另一方面在LLM这样的场景下,finetune本身的开销可能过大以至于完全无法接受了。
0.3. Sparsity in SNN
依照前面的表达,SNN的推理过程可以写作:
可以看到,与ANN不同的是,SNN的推理一般需要在时间上累加,而每个时间步都可能有不同的输入模式。不太正确的比喻是,SNN将ANN中一次传递的信息,分摊在多个时间步上进行处理,提供了理论上的更复杂表达能力的同时,还提高了一个相比于的稀疏性。实验中也发现,相比于普通的ANN,SNN中每个时间步上Input Spike(即)的稀疏性是提高了的。同时,Spike化的Activation一般是1-bit或2-bit的,在每个timestep上需要传输的数据也是减少的。
因此,一个很自然的想法是,能不能借鉴ANN中已经做过的各种优化的思想,利用SNN的1. 低比特Activation/Spike;2. per timestep高稀疏性,在GPU上加速SNN的推理与训练?