摘要 :我们提出了 Kimi Linear,这是一种混合型线性注意力架构。在公平对比下,它首次在多种场景(包括短上下文、长上下文,以及强化学习(RL)扩展范式)中超越了全注意力(full attention)。其核心是 Kimi Delta Attention(KDA):一个具有强表达能力的线性注意力模块。KDA 以更细粒度的门控机制扩展了 Gated DeltaNet,使有限状态 RNN 的“记忆”(memory)得以更高效地利用。我们定制的分块式(chunkwise)算法采用 Diagonal-Plus-LowRank(DPLR) 转移矩阵的特化变体,实现了高硬件效率;与通用 DPLR 形式相比,它显著降低计算量,同时与经典的 delta 规则更加一致。我们基于逐层混合的 KDA 与 Multi-Head Latent Attention(MLA) 预训练了一个 Kimi Linear 模型,具有 3B 激活参数与 48B 总参数。实验表明,在相同训练配方下,Kimi Linear 在所有评测任务上均以显著优势超过纯 MLA;同时 KV 缓存占用最多可降低 75%,在 1M上下文下的解码 吞吐最高可达 6×。这些结果表明,Kimi Linear 可以作为全注意力架构的 即插即用替代方案,在性能与效率上更优,且适用于更长输入与输出长度的任务。为支持进一步研究,我们开源了 KDA 内核与 vLLM 实现,并发布了 预训练与指令微调的模型检查点。
1. Intro
Transformer在推理阶段的瓶颈越来越限制,包括在做RL/长文本任务的时候,Test Time Scaling的需求非常高。Linear Attention提供了一条系统化的降低复杂度的路径,但表达力受限。近日,这种差距逐渐缩小,主要得益于:
- 门控/衰减机制
- Delte Rule
但是纯Linear Attention结构的方法从根本上受限于有限状态容量,因此理论上使得长序列建模与上下文内检索任务在Linear Attention上依旧是受限的。为了解决这种问题,结合softmax与线性注意力的混合架构是一种综合效率与质量的选择。
先前的混合架构工作规模受限、缺乏完整的研究和评测。
关键挑战依旧在于:设计一种在质量上能匹配或超越全注意力,同时在速度与内存上实现显著效率收益的注意力架构 ——这对支撑新一代以智能体与重解码为特征的 LLM 至关重要。
本文提出Kimi Linear,是一种为满足智能体与Test Time Scaling需求而设计、且不牺牲质量的混合线性注意力架构。核心是Kimi Delta Attention(KDA),一个硬件高效的线性注意力模块。KDA以更细的Gating机制扩展了Gated DeltaNet。Mamba2采用head-wise的遗忘门,而KDA则采用Channel-wise的变体。这种细粒度设计能更精确地调控有限状态 RNN 的记忆,从而释放 RNN 风格模型在混合架构中的潜力。
进一步地,KDA引入了对角+低秩(DPLR)的一种特化变体,参数化其状态转移算法,实现了一个定制的chunkwise parallel算法,显著减少计算量的同时与经典的Delta Rule保持一致。
Kimi Linear采用经典的3:1固定比例将KDA和Full Attention交替排列。在长序列任务重使得KV Cache的使用量降低最高75%,同时保留全局信息流。通过与训练与评测,Kimi Linear在短上下文、长上下文、RL Post-training上都能稳定地匹配活超越强力的Full Attention Baseline,并在1M上下文长度下实现了最高的Decode吞吐提升。
Contributions:
- Kimi Delta Attention(KDA) :一种线性注意力机制,在 门控 delta 规则 框架下改进了** 循环记忆管理与 硬件效率**。
- Kimi Linear 架构 :采用 KDA:全局注意力 = 3:1 的混合设计,在** 降低内存占用的同时 超越全注意力质量**。
- 规模化的公平实证 :在 1.4T token 的训练中,Kimi Linear 在短/长上下文与 RL 风格评测上优于全注意力与其他基线;同时** 完整发布内核、vLLM 集成与 检查点**。
2. Preliminary
2.1. Notation
记s的第列;是Hidden State/记忆状态;是包含/不包含对角线的下三角矩阵掩码,分别写作Tril和StrictTril。
Chunk-wise Formulation
假设将序列分为个分块,每块长度为。定义是对应分块内所有的列向量形成的矩阵,记,注意需要。另外,约定,即一个分块的起始元素是上个分块的结束元素。
Decay Formulation
定义累计衰减:,简写。另外地,记,是构成的矩阵。表示细粒度衰减的对角矩阵,且\text{Diag}(\gamma_{[t]}^{i\rightarrow j}):=\prod^j_{k=1}\text{Diag}(\alpha^k_{[t]}), $$\Gamma^{i\rightarrow j}_{[t]}\in \mathbb R^{C\times d_k}是从到形成的堆叠矩阵。
2.2. Linear Attention and the Gated Delta Rule
Linear Attention as Online Learning
Linear Attention维护一组矩阵状态,累计Key-Value关联:
从Fast weight角度,作为associative memory,存储key到value的瞬时映射,更新等驾驭对unbounded correlation objective做一次梯度下降:
不断强化最近一次key-value对,但不能遗忘之前的内容导致对上下文造成干扰。
DeltaNet: Onlinen Gradient Descent on Reconstruction Loss
DeltaNet进一步扩展到:
以学习率进行一步更新:
就是最经典的DeltaRule。这种更新结构是广义Householder变换,支持硬件高效的分块并行化。
Gated DeltaNet as Weight Decay
Gated DeltaNet引入标量遗忘门,得到:
对Fast Weight做了类似weight decay的作用,提供了有效的遗忘机制。另一个角度来说,GDN 也可被视为一种乘性位置编码:其状态转移矩阵数据依赖且可学习,从而放宽了 RoPE 的正交性约束。
3. Kimi Delta Attention: Improving Delta Rule with Fine-grained Gating
我们提出Kimi Delta Attention,这是一种新的Gating Linear Attention变体,将Gated Delta Net的标量decay替换对对角化的细粒度Gating,从而对记忆衰减和位置感知进行更细粒度的控制。
KDA的递推与读出为:
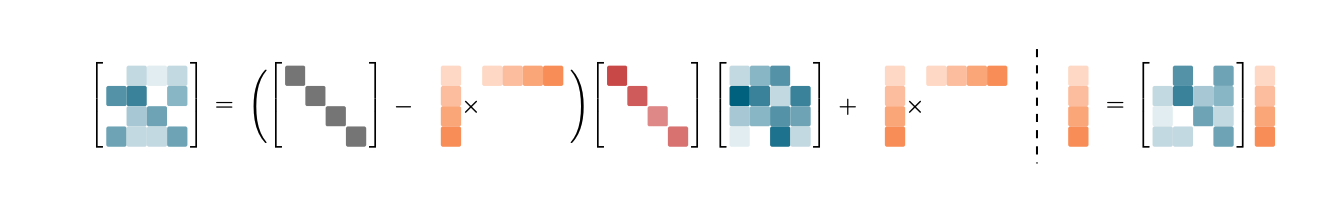
3.1. Hardware-Efficient Chunkwise Algorithm
将上面的递推按照分块的模式下部分展开,可以得到:
WY Representation
WYB表示经常用来打包表示一系列的rank-1更新。遵循Comba的表述,以避免后续额外的矩阵求逆:
其中的辅助向量:
UT Transform
为了减少非矩阵成的FLOPs、提升训练时的硬件利用率,采用UT变换构造三角系统,并用前向代替求拟。
相应地,更新也可以写作chunk-wise的形式:
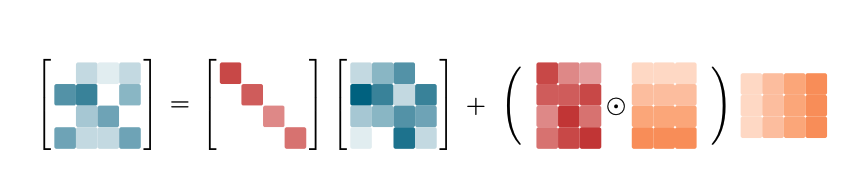
而输出阶段,采用块内并行、块间递归的策略,最大化矩阵乘法/Tensor Core的吞吐:
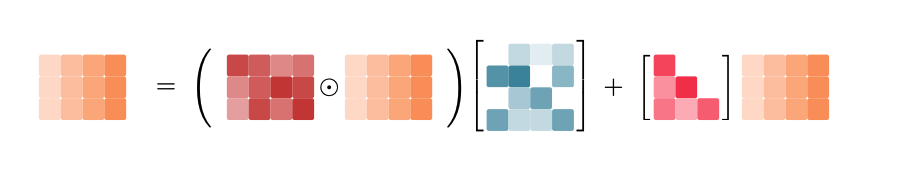
3.2. Efficient Analysis
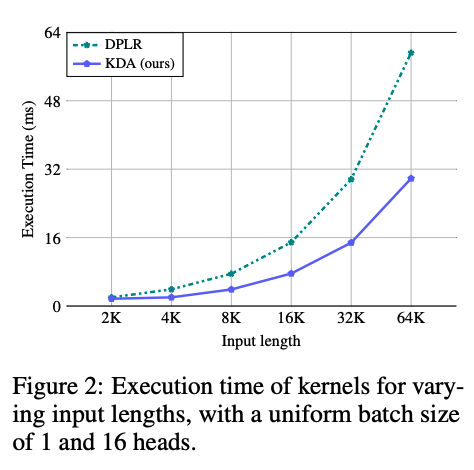
表征能力上,KDA与广义DPLR形式等效,二者都体现了细粒度衰减。但细粒度衰减会在某些除法步骤引入数值精度问题。之前的GLA等采用对数计算、二级分块且全精度的做法来缓解,但对吞吐影响很大;KDA通过把都绑定到,缓解了该瓶颈。
4. The Kimi Linear Model Architecture
Backbone遵循Moonlight,除了细粒度Gating之外,还引入了若干组件进一步增强Kimi Linear表达能力。
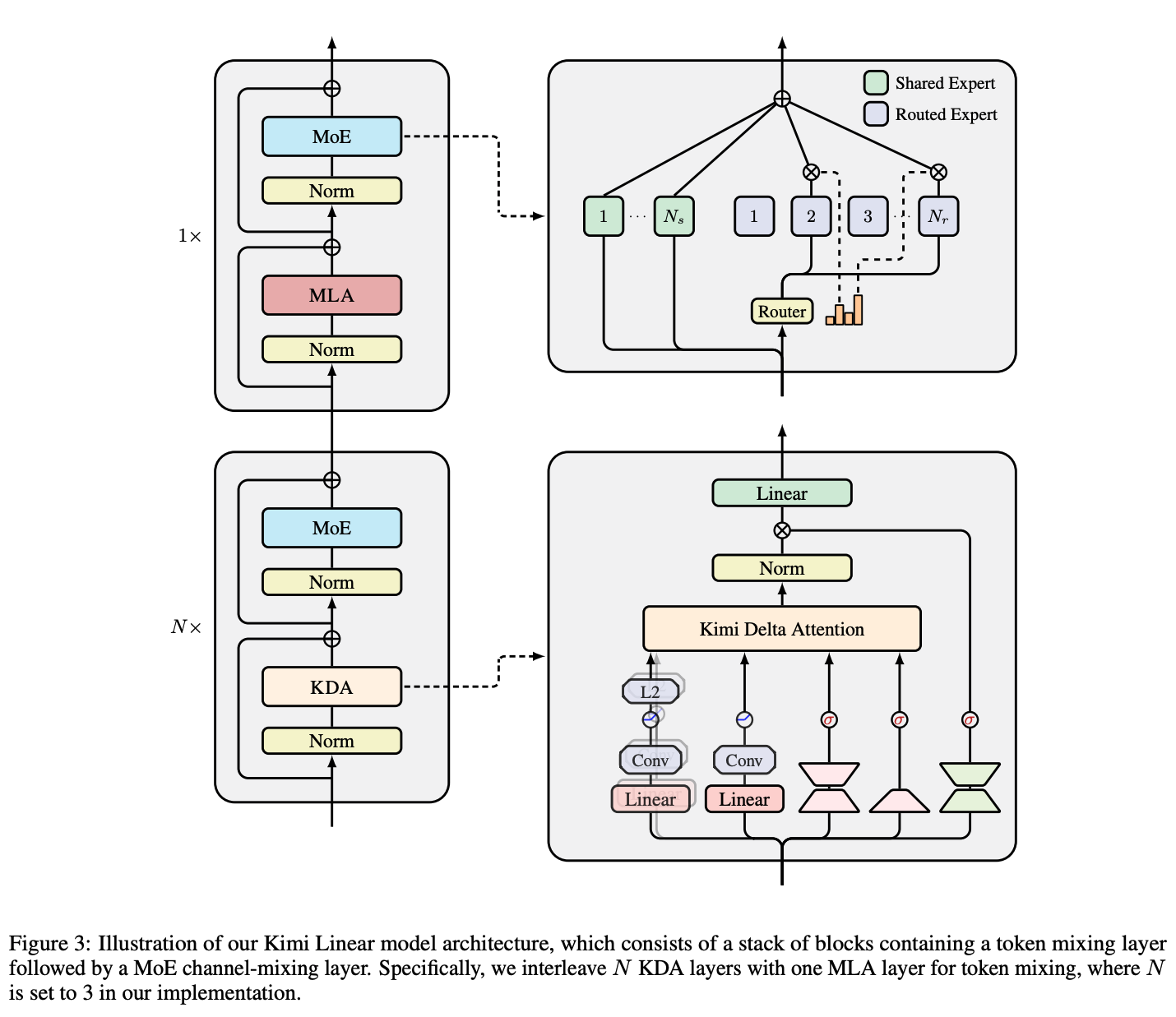
Neural Parameterization
设是第个token的输入表达,KDA每个head的输入:
试验中,对都先做ShortConv再接Swish激活,然后对做L2Norm,提升稳定性。逐通道的遗忘系数通过low-rank projection(的rank等于head的维度)并配合衰减函数来参数化。输出前按头RMSNorm和Data Dependent Gating,并最终通过做输出投影。
Hybrid model architecture
纯线性注意力在长上下文检索上仍是主要瓶颈,因此我们将 KDA 与少量全局注意力(Full MLA) 层混合。出于实现简单与训练稳定的考虑,Kimi Linear 采用 按层交替(layerwise) 而非按头混合(headwise) 的策略。实证显示,3:1 的均匀比例(3 个 KDA 层 + 1 个 Full MLA 层循环)可在质量—吞吐之间取得最佳折中。
No Position Encoding (NoPE) for MLA Layers
Kimi Linear 对所有 Full MLA 层采用 NoPE 。这意味着位置/新近性偏置 完全交由 KDA 承担——KDA 成为主要的** 位置感知算子**,其作用类似或强于短卷积、SWA等辅助组件。我们的发现与一致:** 全局 NoPE 注意力** 配合** 专门的“位置感知”机制**,同样可获得有竞争力的长上下文表现。NoPE 还带来两点工程优势:其一,推理时便于将 MLA 转换为** 高效的纯 MQA**;其二,简化长上下文训练流程——无需对 RoPE 做基频调参或采用 YaRN等方法。
5. Experiments
5.1. Synthetic tests
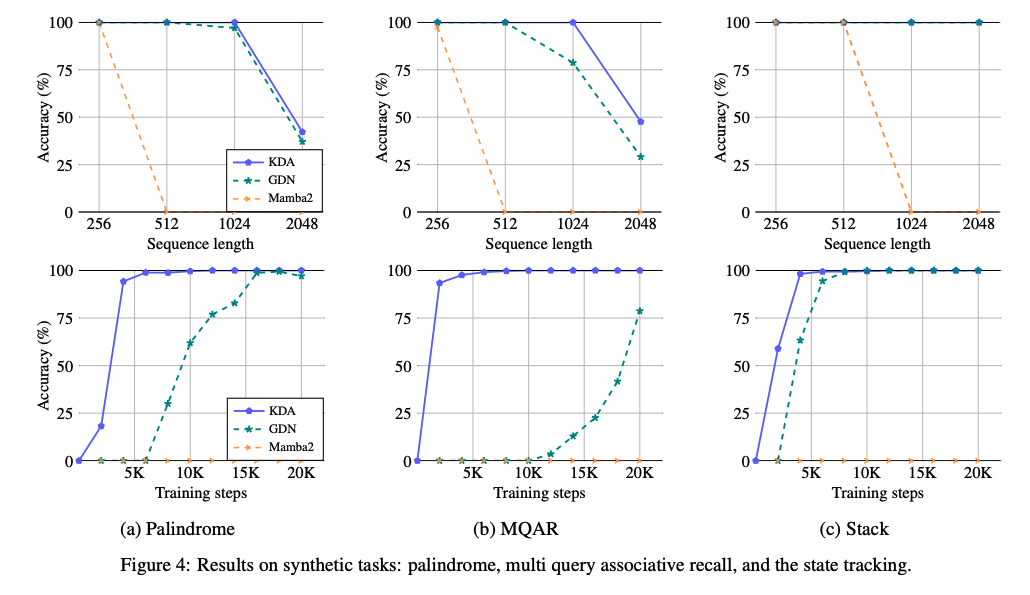
比较小规模的合成实验,2层2head,head dim=128,训练最多20000步。任务包括:
- Palindrome回文,要求模型将给定的随机token序列逆序复制,对Linear Attention类很难,因为需要从固定容量的压缩记忆中精确回溯历史;

- MQAR,Multi-Query Associative Recal,多查询关联检索,主要评估模型在上下文不同位置,对多个query的关联value的检索能力
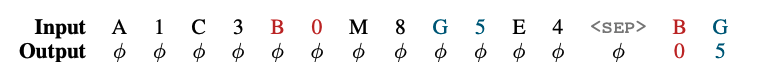
- Stack,LIFO,评估状态跟踪能力,模型需要在一系列
<push> 1 G,<pop> 0 E这样的操作中准确维护多个栈的状态,并且在每次<pop>的时候给出正确元素。
随着序列长度由 256 提升到 2,048,KDA 在三类任务上一致取得最高准确率;在回文与检索密集的 MQAR 上,KDA 的收敛速度明显快于 GDN,验证了细粒度衰减有助于选择性遗忘无关信息、更精确地保留关键信息。此外,在我们的设置下,仅用乘性衰减、且缺乏 delta 规则的 Mamba2 在这些任务上均未收敛。
5.2. Ablation on Key Components of Kimi Linear
在16层、16head上直接做对比,所有模型共享FLOPs与超参:
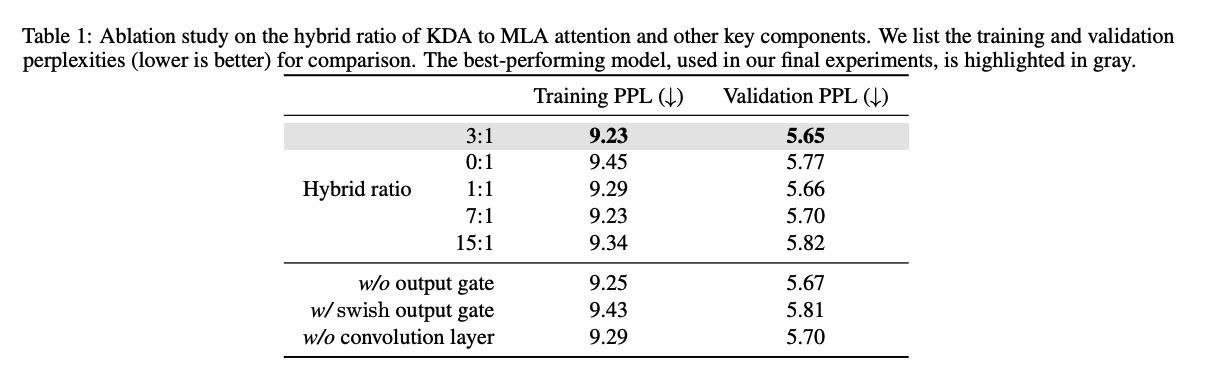
- Output Gate,默认采用Sigmoid,去掉Gating掉点,将output gate改成swish表现显著劣于Sigmoid;
- Shortcut Conv,去掉掉点,因为比较小的Channel-Wise卷积被认为有助于建模局部token;
- Hybird Ratio,发现3:1最好,为什么0:1反而差?可能是没有RoPE的原因
- NoPE vs. RoPE,Kimi Linear在长上下文里更好而RoPE版在短上下文中相近。
我们推测:这源自位置偏置在深度上的分配差异。RoPE 版本里,全局注意力层承载强显式相对位置信号,而线性注意力(如 GDN)仅提供弱隐式偏置,导致全局层过度强调短程顺序——有利于短上下文,却削弱了中途扩展上下文时的灵活性。相反,Kimi Linear 在层间诱导更均衡的位置偏置,带来更强的长程鲁棒性与外推。在长上下文基准上的平均分,Kimi Linear 也最佳。
5.3. Scaling Law of Kimi Linear
j
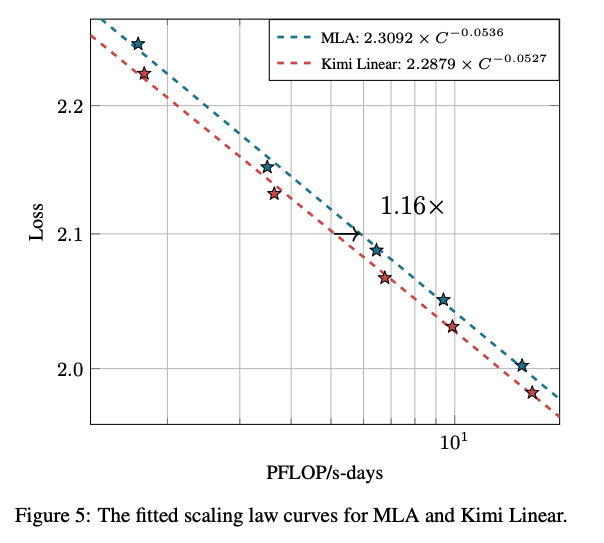
若进一步精调超参,KDA 的 Scaling 曲线还能更优 。
5.4. Experimental Setup
Kimi Linear and baseline settings
将 Kimi Linear 与 ** 全注意力 MLA**、以及** 混合 GDN(GDN-H)做对比。这三者在架构、参数量与训练配置上保持一致以保证公平;整体与 Moonlight 对齐,主要区别是 ** MoE 稀疏度设为 32。
- 每个模型在 256 个专家中激活 8 个 (包含一个共享专家),因此总参数 约 48B ,每次前向激活参数 约 3B 。
- 首层 使用致密层(非 MoE)以保证训练稳定。
- 为验证 NoPE 的有效性,还引入使用 ** RoPE** 的同构 KDA 混合基线,记作 ** Kimi Linear(RoPE)**。
Benchmarks
- 语言理解与推理 :Hellaswag、ARC-Challenge、Winogrande、MMLU、TriviaQA、MMLU-Redux、MMLU-Pro、GPQA-Diamond、BBH。
- 代码生成 :LiveCodeBench v6、EvalPlus。
- 数学与推理 :AIME 2025、MATH 500、HMMT 2025、PolyMath-en。
- 长上下文 :MRCR、RULER、Frames、HELMET-ICL、RepoQA、Long Code Arena、LongBench v2。
- 中文理解与推理 :C-Eval、CMMLU。
5.4.1. Pretraining recipe
- 上下文窗口:4,096。
- 优化器:MuonClip;学习率调度:WSD。
- 总训练 token:共享 1.4T(来自 K2 预训练语料)。
- 学习率:;全局 batch:3,200 万 token。
- 退火与长上下文激活阶段:与 Kimi K2一致。
最终发布的 Kimi Linear checkpoint 使用相同流程,但将总 token 扩至 5.7T(与 Moonlight 匹配),并支持最长 1M 上下文。
5.4.2. Post-training recipe
SFT:在 K2的 SFT 数据上扩充,加入更多推理任务,形成覆盖多领域、重数学与代码的大规模指令调优集。采用多阶段 SFT:先广域通用指令学习,再计划性地聚焦推理密集数据以增强推理能力。
RL:提示集重点整合数学、代码与 STEM 三类数据,以提升推理。在 RL 前,基于起始 checkpoint 预选中等难度样本。
- 为对抗 RL 造成的通用能力退化风险,我们在 RL 期间引入 PTX loss ,即在 RL 进程中并行进行 SFT,所用 PTX 数据既含推理也含通用任务,均为 K2 训练配方的子集。
- 算法:与 K1.5 相同,并加入若干改进技巧:
- truncated importance sampling,缓解rollout 与训练策略不匹配;
- 动态调整 KL 惩罚与 mini-batch 大小(每次迭代更新步数),稳定 RL、避免熵崩塌。
5.5. Main results
5.5.1. Kimi Linear@1.4T results
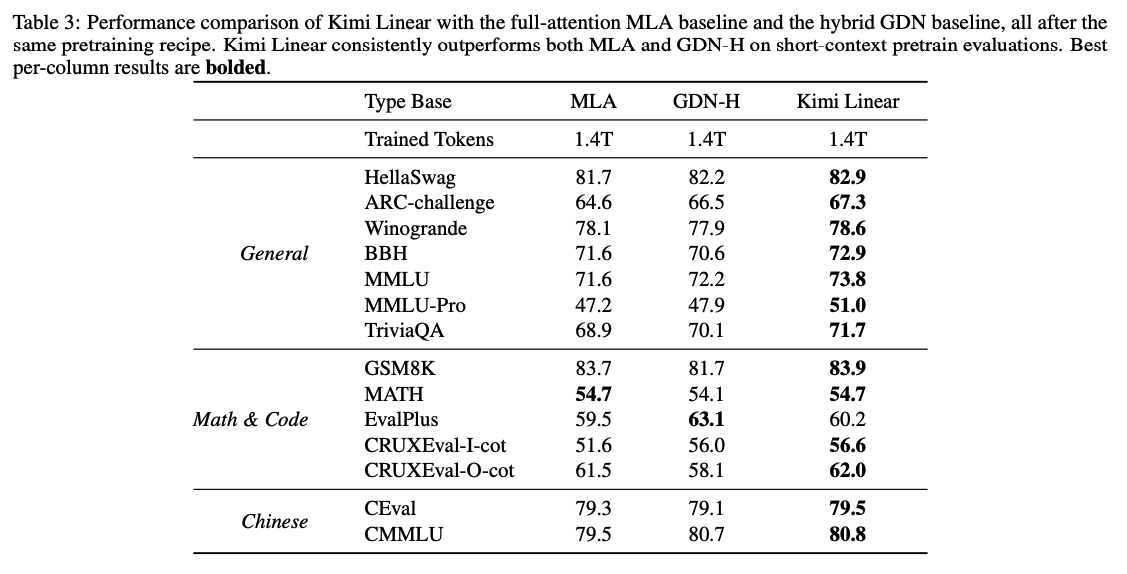
- Pretraining Results
- 通用知识 :在 BBH、MMLU、HellaSwag 等关键基准上均取得最高分。
- 推理 :在数学(GSM8K)与大多数代码任务(CRUXEval)上领先;但在 EvalPlus 上较 GDN-H 略低。
- 中文任务 :在 CEval 与 CMMLU 上取得最高分。
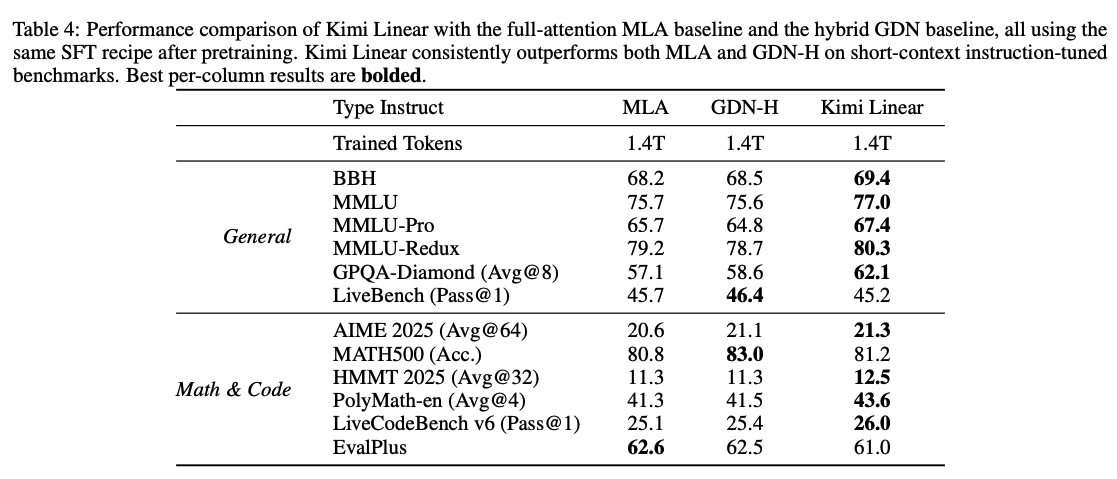
- SFT Results
- 通用任务 :在多种 MMLU 变体、BBH、GPQA-Diamond 上全面领先。
- 数学/代码任务 :在 AIME 2025、HMMT 2025、PolyMath-en、LiveCodeBench 等难度较高的基准上均优于两条基线。
- 虽然在个别项目(如 MATH500 与 EvalPlus)上存在小幅例外,但整体上 Kimi Linear 的优势稳健且显著 ,清晰优于对照模型(GDN-H 与 MLA)。
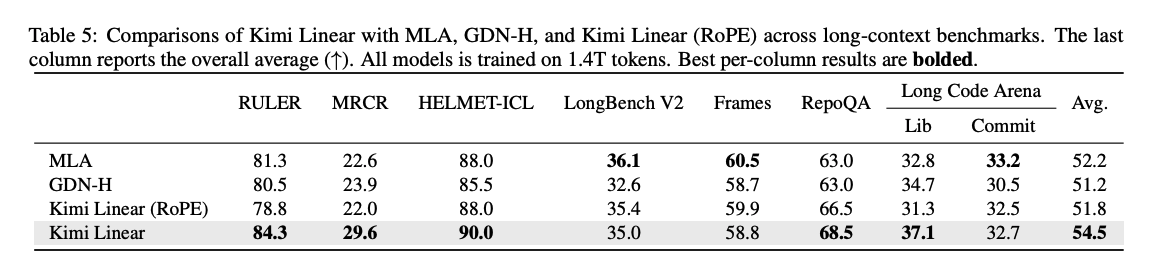
- Long Context
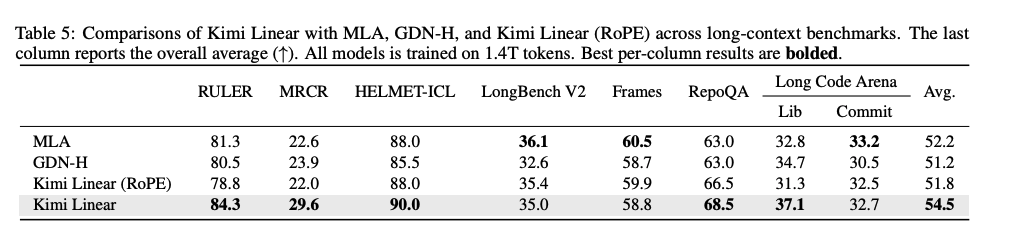
- 在 RULER(84.3)与 RepoQA(68.5)上以显著优势 拿到最高分;
- 除 LongBench V2 与 Frames 外,其他多数任务上也保持领先;
- 总体平均分 为 54.5 ,再次强化了其在长上下文场景中的领先性。
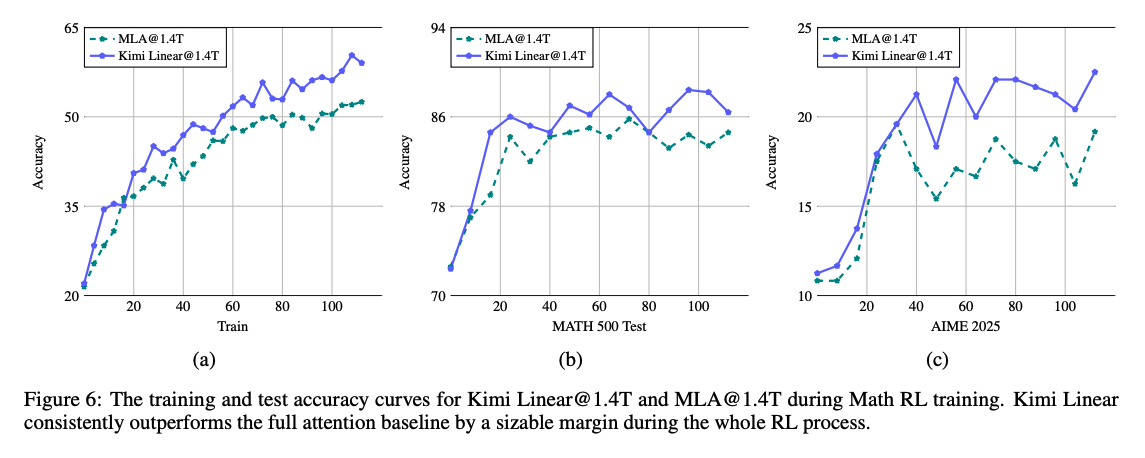
- RL Results
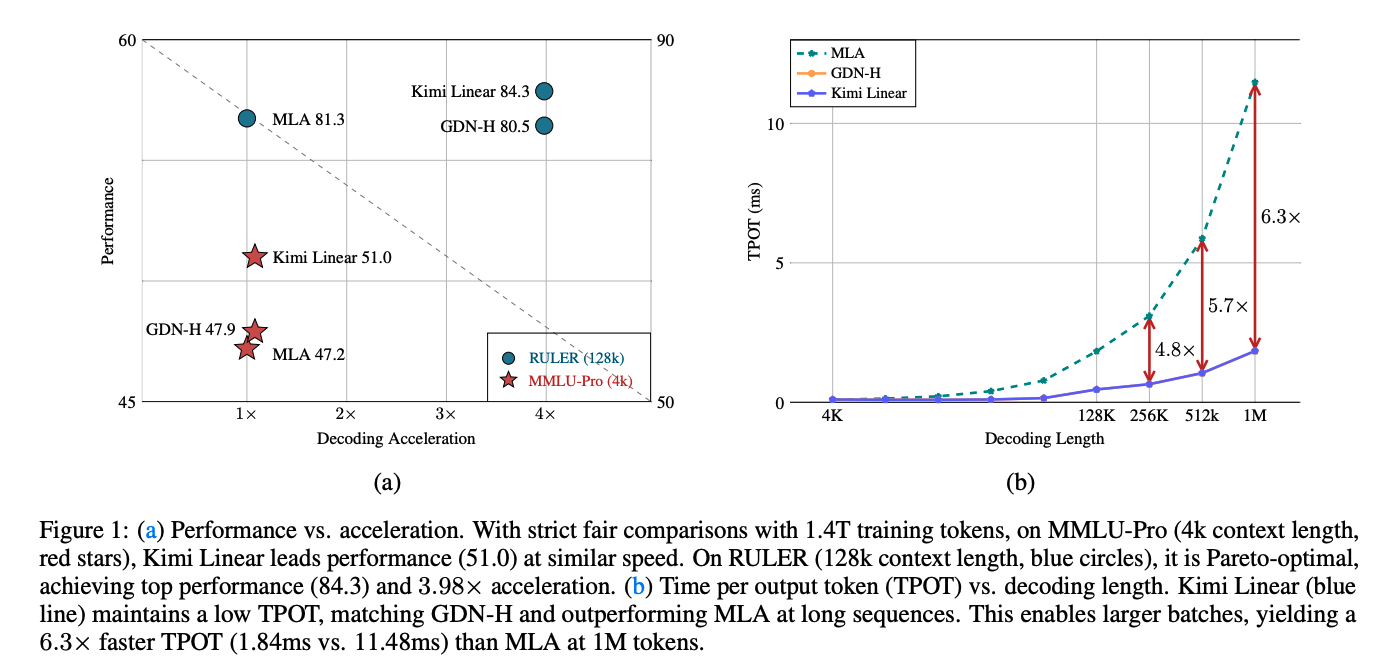
5.6. Efficiency Comparison
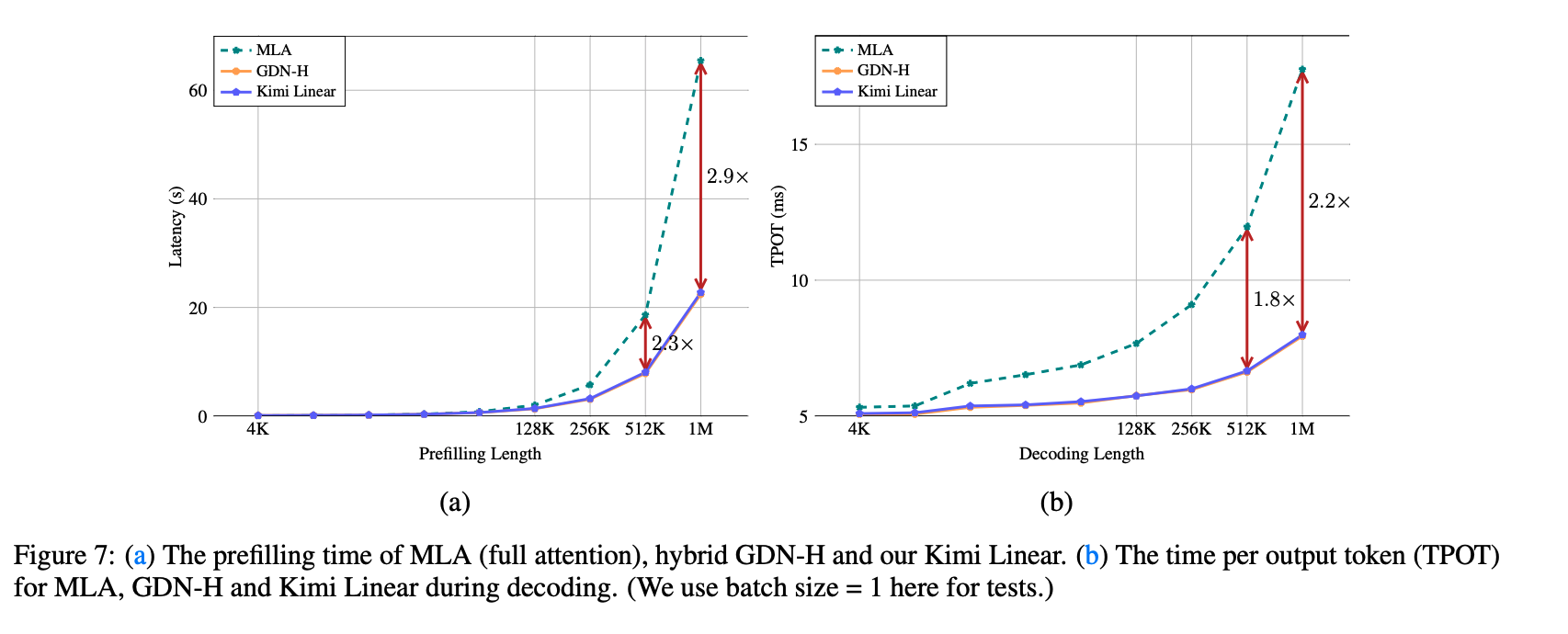
- 尽管 Kimi Linear 引入了更细粒度的衰减机制,但在 prefilling 阶段相较 GDN-H 几乎无额外时延。两者的曲线几乎重合,验证了方法的高效率。
- 随着序列长度增加,混合式的 Kimi Linear 在效率上明显优于 MLA:
- 在较短长度(4k–16k)时与 MLA 相当;
- 从 128k 起显著更快,并在大规模下优势进一步扩大:
- 序列长 512k 时,Kimi Linear 比 MLA 快 2.3 倍;
- 序列长 1M 时,快 2.9 倍。
- 在解码阶段:当上下文长度为 1M 时,Kimi Linear 的每 token 时间(TPOT)比全注意力 快 6×。
6. Discussions
6.1. Kimi Delta Attentino as learnable positin embeddings
标准的Self Attention自己没办法感知到序列的顺序,因此需要显示的位置编码。像RoPE这样的乘性的位置编码,可以通过如下的广义注意力进行分析:
其中第个查询与第个key 的相对位置关系,由累计矩阵乘结果反应。RoPE将定义为块对角矩阵:
共个,每对二维特征分配个字的角频率,由于旋转的性质(如),绝对位置(作用在上的)可以各自独立地施加,并在注意力计算的过程中自动转换为相对位置:
从这个角度看,带Delta Rule的Linear Attention和上面的广义注意力的机制很相似,

因此,Gated Delta Net可以被解释为一种乘性的位置编码,状态转移矩阵是input dependent的,并且可学习,放宽了RoPE的正交约束性,理论上更强.
这也为 RoPE 的已知外推问题提供潜在解法:RoPE 的固定频率容易对训练时见过的上下文长度发生过拟合。一些工作采用部分 RoPE,甚至直接取消显式位置编码(NoPE)。鉴于 GDN 与 RoPE 角色相近,我们在模型中为全局 Full Attention(MLA)选择 NoPE,把位置信息的建模交给所提出的 KDA 来动态学习。
6.2. Relation to DPLR
Gated DeltaNet可以推广为更具表达力的DPLR结构,形式为,S4是静态的DPLR。DPLR引入了更好的表达,但是并行能力很差。
为此,KDA提出一种受约束的DPLR变体:
对应地一般DPLR:
进一步地,通过共享,将它提到式子外面:先对施加细粒度衰减,再通过接近DeltaNet的HouseHolder风格变换,实现高效的状态更新。

上面的PyTorch 风格伪代码给出了分块 DPLR 与 分块 KDA 的实现,关键改进如下:
- 数值稳定性:在分块形式中, 的倒数(如 )会带来不稳定。可用二级分块缓解,但会增加计算与 I/O。KDA 在 DPLR 中令 ,从而移除两步二级分块,减少冗余操作并提升总体效率。
- 矩阵乘减少:相较 DPLR,KDA 在块间与输出计算中额外消去约三次矩阵乘,带来核级加速。
6.3. 复杂度分析
相比于FullAttention:
7. Related Works
7.1. Efficient Subquadratic Attention
Linear Attention

精细的记忆控制、效率权衡、FastWeight。
Gated Linear Attention
LA缺乏softmax的选择性,表达能力不足,因此Gating机制尤为关键。
Sparse Attention
最近的工作趋向于做软硬件协同设计。
Discussion
线性注意力与稀疏注意力是高效长上下文的两条路径。稀疏 在细粒度回溯 上更强,但需保存全量 KV cache 以做选择,因此在推理效率上往往不如仅维护** 常量状态的 线性模型;且稀疏仅做 信息选择**,其表达上限仍受全注意力约束。相反,** 线性注意力遵循“ 压缩即智能**”的理念:用** 定长状态实现泛化;结合 ** Delta 学习规则,其表达能力在理论上可更强。尽管线性注意力常被批评** 检索性弱**,但可通过** 状态扩展等技术缓解。需要指出,线性注意力仍受 硬件实现与 推理基础设施限制。我们的工作用 ** Kimi Linear(与 ** vLLM** 集成)弥补这一点:与全注意力基线竞争,在 100 万 token 的上下文上实现** >2×** 的解码加速。两条路径并非互斥,未来可探索** 线性 × 稀疏的混合模型:既利用线性的 压缩与泛化**,又吸收稀疏的** 精细检索**,进一步提升性能与效率。
7.2 Hybrid Model
Intra Layer or Inter Layer
Discussion
近来的结果显示,混合模型对 RoPE 基频 调整可能敏感,从而使扩展上下文窗口变得困难。为应对此问题,趋势转向引入 NoPE:例如 Falcon-H采用极高基频(如 )把位置编码推向近似 NoPE;SwanGPT 在架构上交错 RoPE-based 层与 NoPE-based 全注意力层。与此方向一致,我们发现将 KDA 层与 NoPE 全注意力混合也是一种高效方案,可更直接地扩展上下文窗口。
8. Conclusion
我们提出 Kimi Linear :一种满足智能体与推理时扩展(test-time scaling)需求、且不牺牲质量的混合线性注意力 架构。其核心 KDA 是带** 按通道门控的高级线性注意力模块,增强了记忆控制,并在混合架构中激活了 RNN 风格模型的潜力。通过以 ** 3:1 的比例交错 ** KDA 与全局注意力**,Kimi Linear 将** 内存占用降低至最多 75%,在 解码吞吐上实现 最高 6.3×** 的提升,并** 超越全注意力基线。我们开源了 ** KDA 内核与** 预训练检查点**,为后续研究提供可扩展、高效的 LLM 方案。