摘要: 门控机制已经被广泛使用,从早期的 LSTM 和 Highway Network ,到最近的state space models、线性注意力,以及 softmax 注意力。然而,现有文献很少专门考察门控本身的具体作用。在这项工作中,我们通过系统化实验,对带门控增强的 softmax 注意力变体 进行了全面研究。具体来说,我们在一个包含 3.5 T token 的数据集上,对 30 个变体进行全面比较,这些变体包括 15B 参数的 MoE模型以及 1.7B 参数的dense模型。我们的核心发现是:一个非常简单的修改——在 Scaled Dot-Product Attention(SDPA)之后对每个注意力头应用 head-specific 的 sigmoid 门控 ——可以稳定地提升性能 。这一修改也提高了训练稳定性、允许使用更大的学习率,并改善了模型的 scaling 性能。通过比较不同的门控位置和计算变体,我们将这种有效性归因于两个关键因素:(1) 在 softmax 注意力中的低秩映射上引入非线性;(2) 施加与 query 相关的稀疏门控分数 来调制 SDPA 输出。值得注意的是,我们发现这种稀疏门控机制可以缓解massive activation 和 attention sink,并提升长上下文外推的性能。我们也公开了相关代码和模型,以促进后续研究。此外,最有效的 SDPA 输出门控已经被应用在 Qwen3-Next 模型中。
1. Intro
最近的各种工作,其实gate的主要是MoE中的专家。本文有一个有趣的发现:即使将专家的数量减少到1,Gating相比于非Gate也是有更好的作用的。这意味着Gating本身就具有一定的价值,不只是router的一部分。
本文研究在标准softmax注意力的情景下、不同的位置引入Gating,探索Gating本身的内在机制,发现:
- 对SDPA输出做head specific的Gating带来了最显著的性能提升
- SDPA还改善了训练稳定性,几乎消除了Spike Loss
本文认为Gating中两个因素起了有效的作用:
- Non-Linearity,value和输出的投影两个连续的Linear层可以被重写成一个Low-rank的Linear Projection,而添加Gating提高了这个位置的表达能力;
- Sparsity,稀疏性消除了massive activation和attention sink的问题。

2. Gated-Attention Layer
2.1. Preliminary: Multi-Head Softmax Attention
给定为长度为的输入,Transformer的计算为:
四个阶段。其中部分称为Scaled Dot Product Attention SDPA。
2.2. Augmenting Attention Layer with Gating Mechanisms
Gating:
可以看作一种动态的滤波器,通过有选择地保留/抹除的信息来控制信息流1。
本文研究的内容包括:
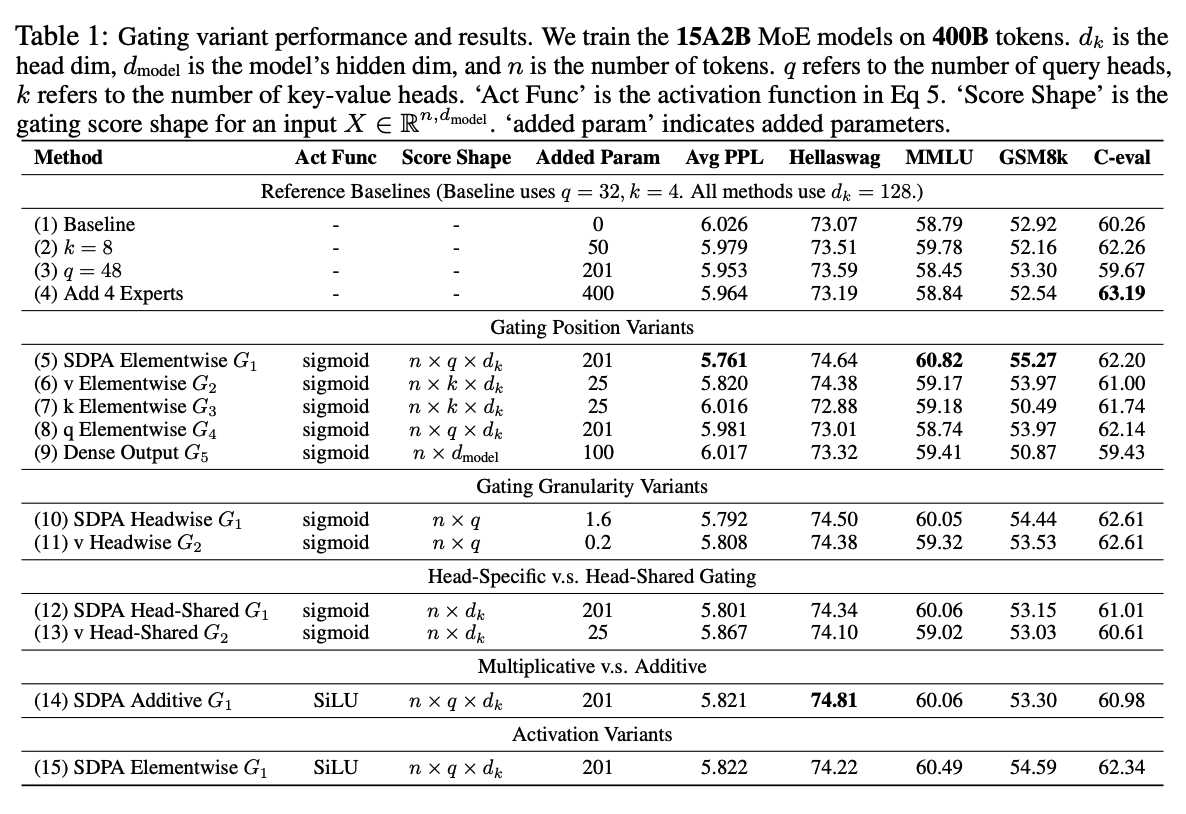
- Position,包括:
- 在QKV之后做,图1的G234
- 在SDPA输出之后,G1
- 在最终的输出之后,G5
- 粒度:
- Headwise,一个标量Gating分数调控一整个头的输出
- Elementwise,细粒度调控
- Head Specific or Shared
- Head-Specific,每个head有自己的分数
- Head-Shared,共享和分数
- 乘性 or 加性,即
- 激活函数,包括
- SiLU
- Sigmoid
- 考虑原理还加入了RMSNormh和Identity Mapping
最终除了额外说明的,均采用head-specific、乘性、sigmoid。
3. Experiments
3.1. Experiments Setups
在 MoE 模型(总参数 15B,其中激活参数 2.54B,记作 15A2B)和Dense(总参数 1.7B)上开展实验。15A2B MoE 模型使用 128 个专家、top-8 的 softmax 门控、fine-grained experts、global-batch LBL和 z-loss。在注意力部分采用GQA。在一个包含 4T 高质量 token 的数据集子集上训练模型,涵盖多语言、数学和通用知识内容。序列长度设为 4096。更具体的配置,比如学习率和 batch size(bsz),会在各小节中介绍。其他超参数遵循 AdamW 优化器的默认设置。由于门控引入的参数和计算量相对较小,门控带来的 wall-time 延迟低于 2%。
在多个常用基准上做 few-shot 测试,包括:
- Hellaswag (英文);
- MMLU (通用知识);
- GSM8K (数学推理);
- HumanEval (代码);
- C-eval 和 CMMLU (中文能力)。
在多种 held-out 测试集上评估 perplexity (PPL),涵盖英文、中文、代码、数学、法律和文学等不同领域。
3.2. Main Results
3.2.1. Gated Attention for MoE models
1k Step warmup到,然后cosine衰减到,global batch = 1024,总共训练100k step。
观察到:
- SDPA和output上加Gating最有效
- Head-Specific的Gating很重要
- 乘性的Gating比加性的Gating更好
- Sigmoid更好
3.2.2. Gated Attention for Dense Models
Gating的时候还减小了FFN的宽度,保持总参数规模不变。
对于在 400B tokens 上训练的 1.7B 模型,我们使用最大学习率和 batch size 为 1024。在 3.5T tokens 的训练中,我们将最大学习率提高到,batch size 提升到 2048。
观察到:
- Gating减小了Spike Loss,提升了训练稳定性,因此上表还有各种各样的不同的learning setting进一步试验,发现:
- Gating在很多种Setting下都有用
- Gating能够提高稳定性并且促进scaling
总结而言,我们识别出SDPA 的 element-wise 门控 是增强注意力机制最有效的方式。在 SDPA 输出处加入门控使得在较大学习率和 batch size 下训练仍然稳定——在这种 regime 下 baseline 通常会变得不稳定。这表明,在使用门控时,最优超参数配置会发生改变。在实践中,一种有效利用门控的方式是:从 baseline 的最优 batch size 开始,适度提高学习率 。进一步同时调节 batch size 和学习率可能会带来额外收益。
4. Analysis: Non-Linearity, Sparsity, and Attention-Sink-Free
在本节中,我们通过一系列实验来探索,为什么这样一个简单的门控机制能够带来显著的性能与训练稳定性提升。根据我们的分析,有如下几点结论:
- 增强非线性的门控 (gatings enhancing non-linearity)会稳定地带来性能收益;
- 最有效的 SDPA 按元素门控(elementwise gate) 会引入强烈的** 输入依赖稀疏性**(input-dependent sparsity),这进一步有助于消除 “massive activation” 和 “attention sink” 现象。
4.1. Non-linearity Improves the EXpressiveness of Low-Rank Mapping in Attention
有一些工作在SDPA输出上使用group norm,本文在每个head concat之前独立应用RMSNorm(即Table 3的(5)),发现几乎不引入新参数的情况下显著降低了PPL。
考虑第个head的第个Token的输出:
指注意力分数。可以看出,由于,可以把合并为作用在上的一个Low Rank Linear Injection,而在使用GQA的时候在不同的head之间共享,进一步降低了表达能力。
由于在两个线性变换之间加入非线性可以提升其表达能力,考虑:
两种写法分别对应了前面的G2和G1,另外这个式子也尝试解释了为什么G5这种修改不起作用,因为没有在和之间添加非线性。
另外注意到,G1位置添加的加性门控,通过SiLU也引入了一些非线性,所以额外做两个实验:
- 在G1位置只加一个SiLU而不引入额外参数,发现只带来小幅度PPL降低;
- 加性Gating中移除SiLU,发现效果进一步变差了
这两个实验说明performance的提升基本是因为非线性。
4.2. Gating Introduces Input-Dependent Sparsity
对G2和G1的进一步研究如下。
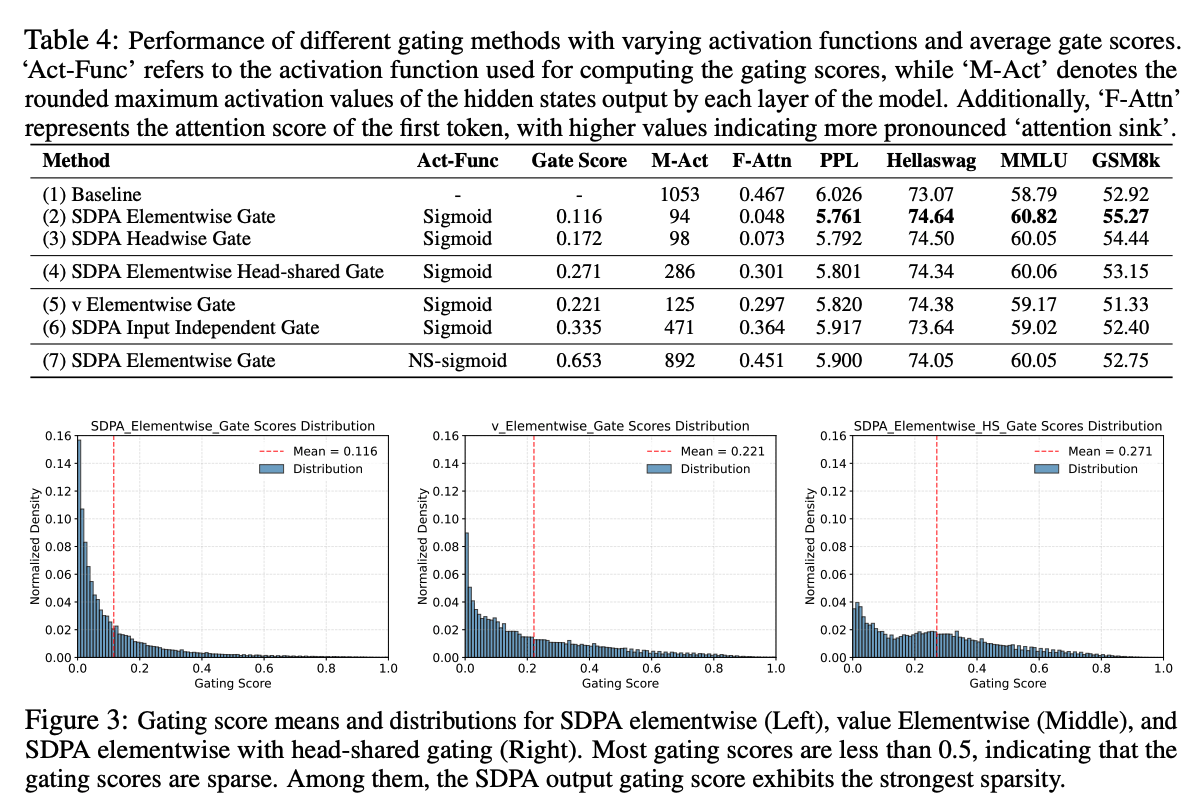
观察:
-
Effective Gating Score are Sparse,因为G1相比于其他的有最低的avg Gate Score,并且在0附近高度集中;
-
Head-Specific Sparsity Matters,因为不这么做掉点,这也与以往研究发现“不同注意力头捕捉输入的互补方面”是一致的
-
Query-Dependency Matters,可能是因为在G2上只和Value有关而和现在的query无关,是说如果Gating Score和query有关,则其sparsity更有效,具体来说:
- SDPA输出的Gating分数是由当前的query产生的
- 而value的Gating分数是由历史Key和Value产生的
这暗示了Gating Score的稀疏性更偏重于为当前的query过滤掉无关的上下文,而不是根据上下文本身进行gating
为了进一步验证,提出了Table4 (6)的Inpute Independent的Gating,发现能比baseline强(因为有non-linearity),但是强的很有限(比不过上面其他任何一个变种)
-
Less Sparse Gating is Worse,尝试解决这个问题构造了一种非sparse的Gating:
发现能有提升但是比sparse的都差。
4.3. SDPA Output Gating Reduces Massive Activation and Attention-Sink
基于前面关于门控在 SDPA 输出处引入输入依赖稀疏性的观察,我们假设:这种机制可以过滤掉与当前 query token 不相关的上下文,从而缓解 attention sink。为验证这一点,我们分析了注意力分数的分布(在所有头上取平均)以及分配给首 token 的注意力比例。
有一些观察发现,activation很大2会导致这个Token分配到的query很大,影响模型性能。在上面的Table4中也可以看到计算了M-Act,而采用了Gating的方法显著小一些,并且越小的模型表现也越好。
观察到:
- G1使用 head-wise 与 element-wise 的 query 依赖 sigmoid 门控,可以大幅降低分配给首 token 的注意力比例,并减少 massive activations
- 强制在各头之间共享门控分数,或者仅在 value 投影之后加入门控,虽然同样会减弱 massive activations,但并不能降低分配给首 token 的注意力分数。这进一步强调了 head-specific 门控的重要性,也表明 massive activations 并非 attention sink 的必要条件
- input independent或者降低稀疏性会强化 massive activations 与 attention sink 两种现象
综合以上观察,我们可以认为:对 SDPA 输出进行输入依赖、head-specific 的门控,会引入显著稀疏性,从而缓解 attention sink。此外,SDPA 输出的稀疏化会减少模型内部的 massive activations,稀疏程度越高,激活值越小。这也可能解释了门控带来训练稳定性提升的原因:通过减少 massive activations,模型在 BF16 训练时对数值误差不那么敏感。 我们还观察到,massive activations 主要源自较浅的层(例如第 5 层),此时 FFN 会产生较大的值,这与 [51] 的发现一致。一旦这些大激活值被加到 residual 流中,它们会通过 pre-norm 机制在后续层中持续传播。这与 sandwich normalization提升训练稳定性的效果相吻合(见表 2 第 7 行):对 FFN 输出施加 LayerNorm,可以阻止这些大激活值进入 residual 流。
4.4. SDPA Output Gating Facilitates Context Length Extension
基于“无 attention sink”这一模式,我们进一步评估 SDPA 门控在长上下文场景中的效果。具体地,我们对在 3.5T tokens 上训练的模型进行上下文长度扩展:(1)将 RoPE 的 base 从 10k 提升到 1M;(2)在序列长度为 32k 的数据上继续训练 80B tokens ,得到上下文长度为 32k 的模型;(3)随后使用 YaRN 将上下文长度进一步扩展到 128k。
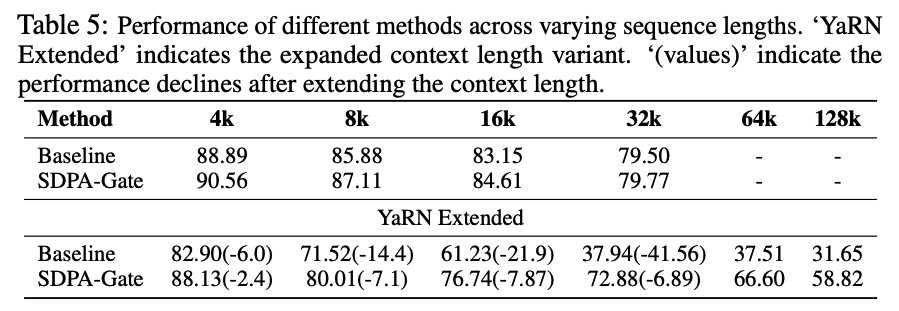
观察:
- 在 32k 设置下,带门控的模型略优于基线。这表明,在训练长度范围内 ,attention sink 现象未必会损害模型的长上下文性能
- 当使用 YaRN 将上下文扩展到 128k 时,基线与带门控模型在原先的 32k 范围内都出现了性能下降。这一现象与已有对通过修改 RoPE 进行上下文扩展的工作是一致的。不过,带门控模型的性能下降更不明显
- 在 64k 与 128k 的上下文长度下,带门控的注意力模型明显优于基线
基于上述观察,我们推测:加入门控有助于模型适应上下文长度扩展。一种可能解释是:基线模型可能依赖 attention sink 来调整注意力分布推导了修改 RoPE 对注意力与隐状态分布的影响。当使用 YaRN 等技术修改 RoPE 的 base 时,这种基于 attention sink 的模式难以在无需额外训练 的条件下适应,从而导致性能明显下降。相比之下,带门控的模型主要依赖输入依赖的门控分数 来控制信息流,因此对这类改动更加鲁棒。
5. Related Works
5.1. Gating in Neural Networks
门控机制在神经网络中已经被广泛采用。早期工作如 LSTMs 与 GRUs 引入门控来调节跨时间步的信息流,通过有选择地保留或丢弃信息来缓解梯度消失/爆炸问题。Highway Networks 将这一思想扩展到前馈网络,使得训练非常深的架构成为可能。SwiGLU 则将门控机制引入 Transformer 的 FFN 层,增强其表达能力,并成为许多开源 LLM 的标准组件。
5.2. Attention Sink
StreamingLLM 正式提出了 “attention sink”,其中某些特定 token 会获得异常大的注意力分数。类似地,在 ViT 中,一些冗余 token 会充当“registers”用于存储注意力分数。随后,Massive Activation 显示,大量注意力分数会被分配给那些具有巨大激活值的 token。
为了解决attention sink的问题,有的方法采用未归一化的sigmoid注意力代替softmax3,或者在softmax注意力之后Clip/Gate,同时也有的工作认为这其实是softmax自有的一种bias,不应该直接去修改它。
6. Conslusion and Limitations
本工作系统性地研究了 softmax 注意力中的门控机制,揭示了其在性能、训练稳定性和注意力动态方面的显著影响。这个简单的机制:
- 增强了非线性;
- 引入了输入依赖的稀疏性;
- 消除了“attention sink”。
此外,门控还促进了上下文长度的扩展,使模型能够在无需重新训练的情况下有效地泛化到更长序列。我们将发布这些“无 attention sink”的模型,为未来关于注意力机制的研究提供基础。
更广泛地看,非线性对注意力动态及整体训练过程的影响仍远未被充分探索。我们没有给出 attention sink 如何影响模型长序列泛化能力的理论解释。
真是只有大公司才能做的工作啊,在1.7B的模型上面做这么多train from scratch的Ablation Study,太狠了。