摘要: LLM表现出色,但计算与显存/内存开销都非常大。量化可以降低内存占用并加速推理。然而,现有方法往往难以同时兼顾精度与硬件效率。我们提出 SmoothQuant:一种免训练、保持精度、通用型的PTQ方案,使 LLM 能够实现W8A8量化。基于一个关键事实:权重量化相对容易,而激活量化更难,SmoothQuant 通过一个数学等价的变换,将激活中的outliers“平滑”掉——在离线阶段把量化难度从激活迁移到权重上。SmoothQuant 让 LLM 中的所有矩阵乘都能进行 INT8 的权重与激活量化,覆盖 OPT、BLOOM、GLM、MT-NLG、Llama-1/2、Falcon、Mistral、Mixtral 等模型。实验显示,在几乎不损失精度的前提下,可获得最高 1.56× 推理加速与 2× 内存降低,甚至能在单机节点内提供 530B 参数量级 LLM 的服务。我们的工作提供了一套开箱即用方案,降低硬件成本并推动 LLM 的普惠化。
1. Intro
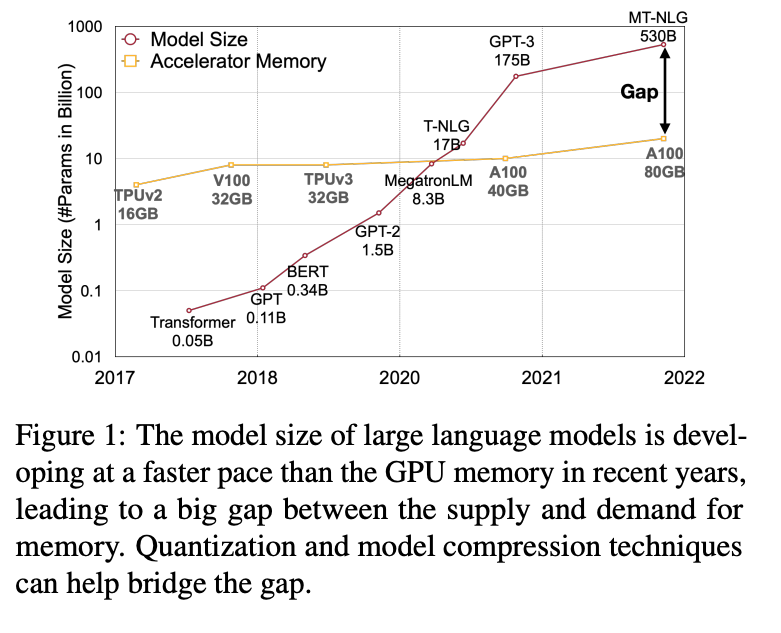
GPT3有175B参数,用FP16至少要350G内存,所以大家都开始关注量化。
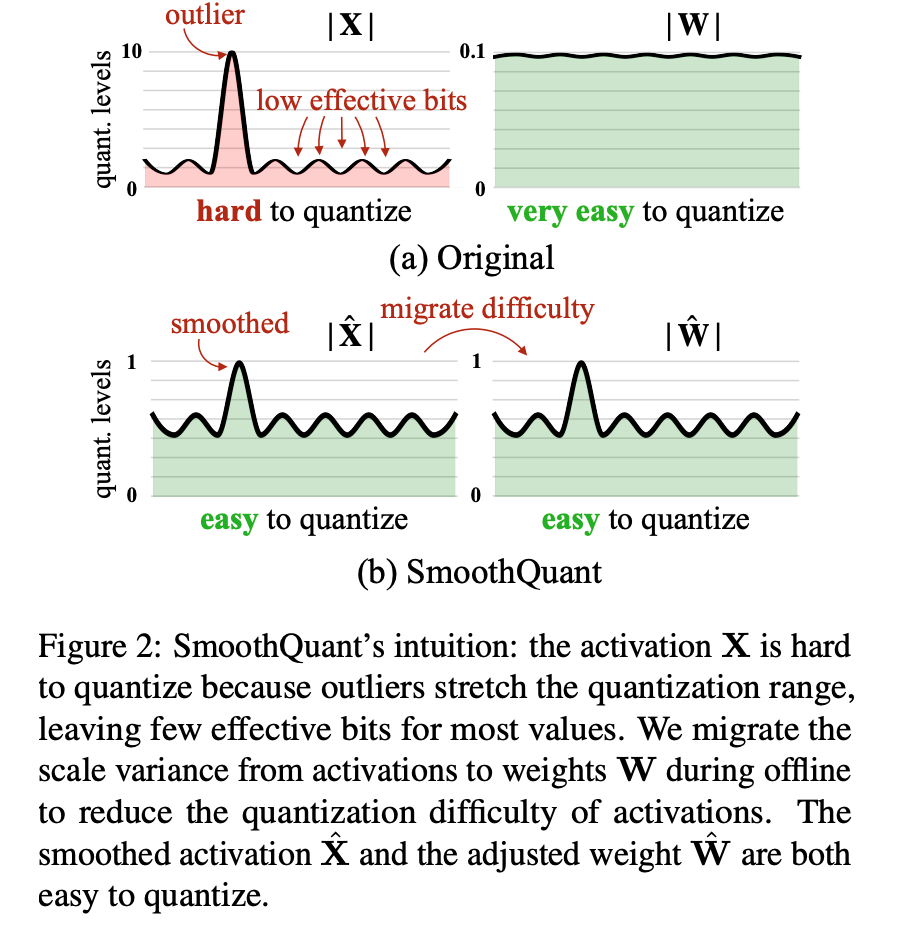
LLM的activation量化起来很困难,因为LLM大了之后会出现一些幅值非常大的outlier,如果还按照之前的方法做量化,这些outlier会把其它的较小的数全部都压扁到一两个level中,精度就完全没有了。ZeroQuant做了per-token的activation量化、group-wise的weight量化,在175B的时候没有精度;LLM.int8()引入了进一步的混合精度,把outlier保留为FP16,其他的用INT8,但是在硬件上很难加速。
本文基于一个观察:尽管激活因为 outlier 的存在而远比权重更难量化,但不同 token 在各个 channel 上的变化模式非常相似。 提出SmoothQuant,将量化难度从activation迁移一部分到weight上,提出一种数学等价的per-channel缩放,抹平不同channel之间的幅值差异。
实验表明 SmoothQuant 具备良好的硬件效率:它能在 PyTorch 上保持 OPT-175B、BLOOM-176B、GLM-130B与 MT-NLG 530B的性能,带来最高 1.51× 加速与 ** 1.96×** 内存节省。SmoothQuant 也很容易落地:我们将其集成到当前 SOTA 的 Transformer serving 框架 ** FasterTransformer** 中,相比 FP16 可实现最高 ** 1.56×** 加速并将显存占用减半。更重要的是,SmoothQuant 能让像 OPT-175B 这样的大模型在** 只用 FP16 一半数量的 GPU的情况下完成部署并且更快,同时还支持在 单个 8-GPU 节点内提供 ** 530B 模型的服务。我们的工作通过提供一套开箱即用方案降低 LLM 服务成本,从而推动 LLM 的普惠化;我们也希望 SmoothQuant 能启发未来更多对 LLM 的应用。
2. Preliminaries
本文主要研究整数均匀量化:
把float输入量化为INT8,其中是步长,是rounding,是比特数。注意本文假设数值中心点就是0,不是0的情况下可以引入零点偏移,方法是类似的。
一般采用最大值计算,从而保持对精度有关键作用的outliers。
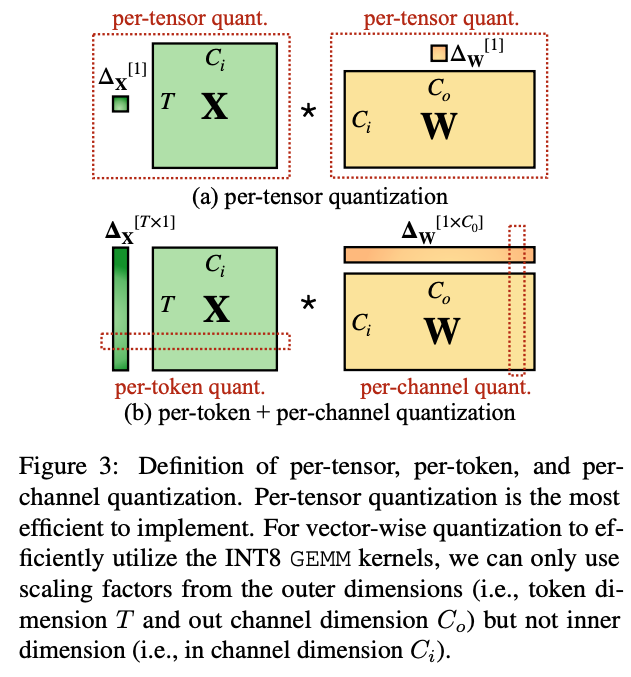
量化的粒度如下图所示。