摘要: 视觉变换器(ViTs)在各种计算机视觉应用中已经达到了最先进的性能。然而,这些模型具有相当的存储和计算开销,这使得它们在边缘设备上的部署和高效推理变得具有挑战性。量化是一种减少模型复杂度的有前景的方法,而二进制算术管道可以使量化模型执行高效的仅整数推理。不幸的是,二进制算法基于卷积神经网络中的均匀性条件,这不适用于ViTs中的非线性组件,使得ViTs的仅整数推理成为一个开放问题。在本文中,我们提出了I-ViT,一种ViTs的仅整数量化方案,以使ViTs能够使用整数算术和位移来执行整个推理的计算图,而无需任何浮点算术。在I-ViT中,线性操作(例如,MatMul和Dense)遵循带有二进制算术的仅整数管道,非线性操作(例如,Softmax,GELU和LayerNorm)通过所提出的轻量级仅整数算术方法进行近似。更具体地说,I-ViT应用了所提出的Shiftmax和ShiftGELU,这些方法设计为使用整数位移来近似相应的浮点操作。我们在各种基准模型上评估了I-ViT,结果显示仅整数INT8量化的准确性与全精度(FP)基线相当(甚至略高)。此外,我们利用TVM在GPU的整数算术单元上进行实际硬件部署,与FP模型相比,实现了3.72∼4.11×的推理加速。Pytorch和TVM的代码已在https://github.com/zkkli/I-ViT上发布。
1. Intro
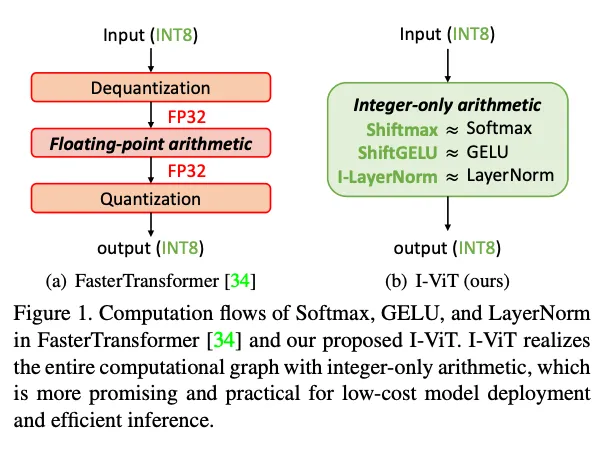
传统的CNN相关的量化工作中一般要求被量化的操作具有“齐次性”,只适合线性或者分段线性的操作。但是ViT中的GELU,Softmax等操作都不是线性的。对比的FastTransformer直接保留了中间的FP32操作(防止掉点),代价是推理非常慢,因为推理速度完全受制于浮点运算单元等,而它们的性能显然不如纯整型的计算过程。
Contribution:
- “the first work on integer-only quantization for ViTs”
- novel light-weight integer approximations for non-linear operations, in particular, Shiftmax and ShiftGELU use integer bit- shifting to accomplish most arithmetic, which fully benefit from the efficient hardware logic.
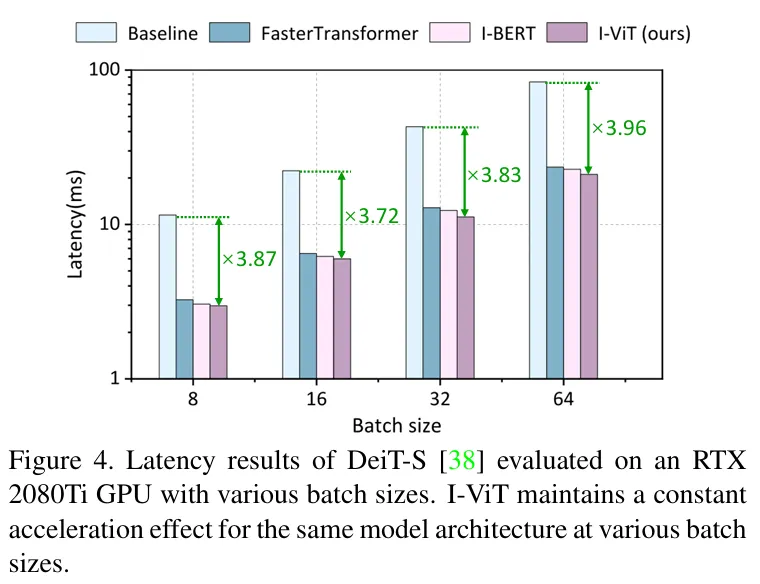
- evaluated on various models for the large-scale classification task, achieving compression with similar (or even slightly higher) accuracy. Moreover, we de- ploy I-ViT on an RTX 2080Ti GPU using TVM, which accelerates the integer-only inference of ViTs with Turing Tensor Cores, achieving a 3.72∼4.11× speedup over the FP model
2. Related Works
2.1. Vision Transformers
ViT, DeiT, 总体来讲在大数据集上超过了传统的基于卷积的神经网络,但是参数量很大,计算的overhead很高。
2.2. Model Quantization
之前的量化工作集中在CNN上,比如DoReFa,LQ-NET,LSQ,但是在ViT上没用。
ViT上的量化工作有Q-ViT,PTQ4ViT,FQ-ViT,RepQ-ViT。但是上面这些量化的工作在inference的过程中还是需要有浮点的介入(Quantization & dequantization的过程),效率不高。
2.3. Integer-only quantization
相比有浮点介入的操作,纯整型的pipeline效率肯定更高一些。I-BERT在BERT上实现了纯整型的推理,但是中间的高阶多项式推理的开销比较大,并且两者使用的数据不同,分布不同,I-BERT中的估计不一定准确。在这篇文章之前还没有在ViT上实现的纯整形量化。
3. Methodology
3.1. Overview
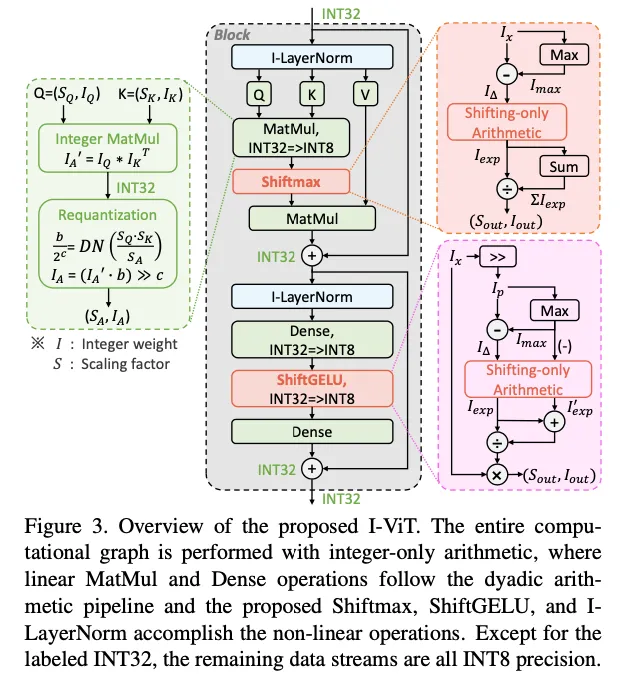
Formula:
Multi-head Self-Attention:
Multi-Layer Perceptron:
量化是均匀对称量化:
上面量化的操作只适合线性的操作而不适合softmax等非线性的操作,因此文章中提出了一些型的方法逼近原本的非线性操作,并且利用移位等操作减小开销。
3.2. Dyadic Arithmetic for Linear Operations
输入要包括和两个参数,比如输入和,矩阵乘的过程写作:
然后要把 reduce到INT8上来:
缩放因子S都是浮点数,但是一般重新scale到
所以最终有:
这个操作过程中就不涉及任何浮点数,只有纯整型的操作了。
3.3. Integer-only Softmax: Shiftmax
普通softmax:
文章里做改进的实际上也是减去max之后的safe-softmax:
近似:
最终有:

3.4. Integer-only GELU: ShiftGELU
,所以
用Shiftmax里面的估计:

3.5. Integer-only LayerNorm: I-LayerNorm
纯整数算均值和方差都可以,但是开方不行,所以用下面这种迭代的方法估计:
其中的初始值是。最开始设计的收敛判定是,但是latency可能会受影响。后面改成固定的10次迭代,大部分情况下都能收敛。
4. Experiments
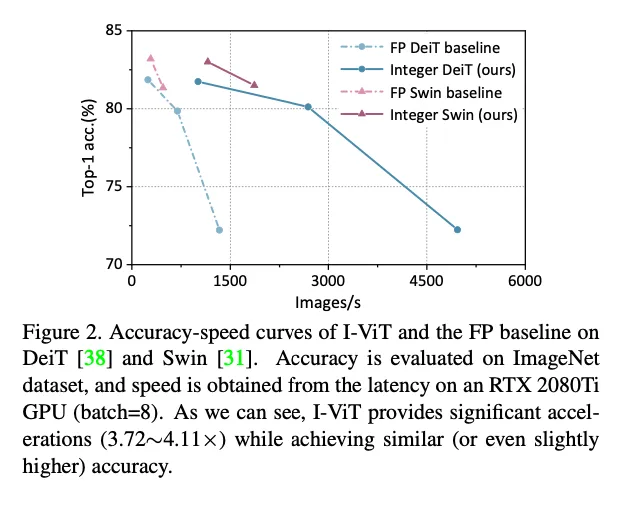
We evaluate I-ViT in both accuracy on the large-scale classification task and latency on the practical hardware to fully demonstrate the superiority, and I-ViT can accelerate over the FP model while achieving similar (or even slightly higher) accuracy.
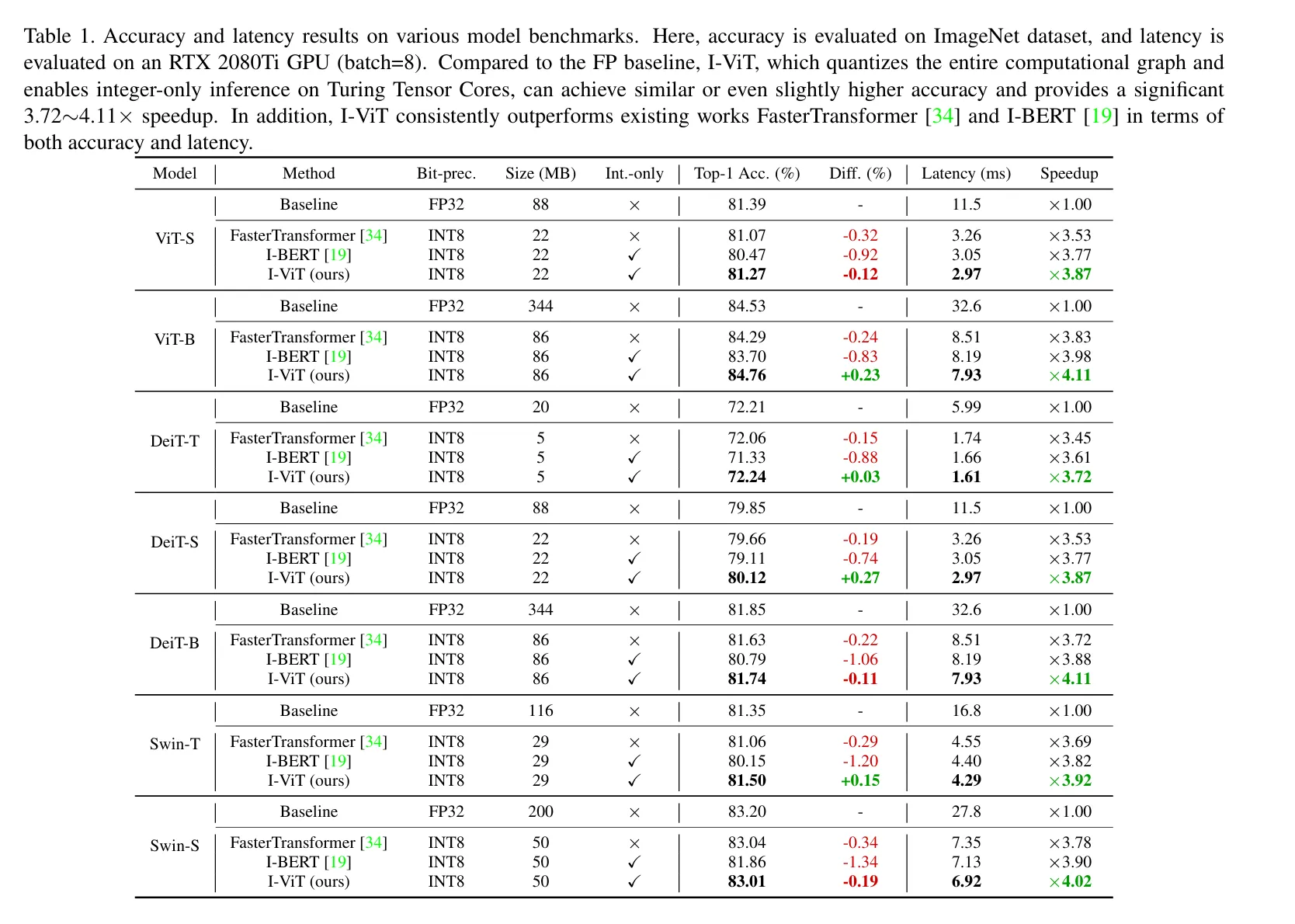
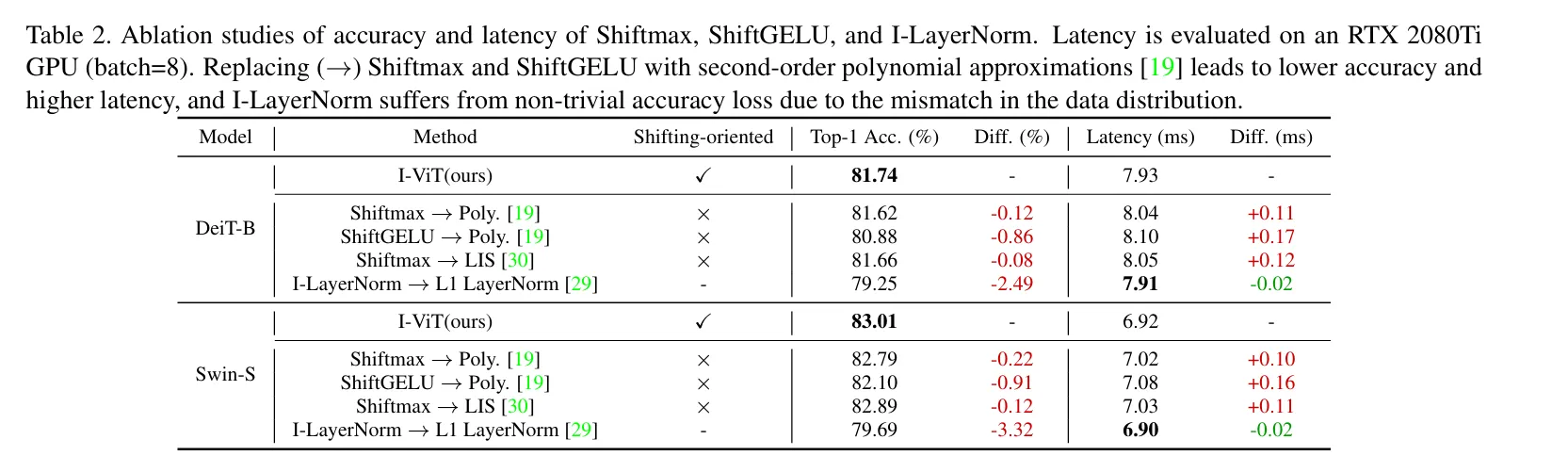
跟FP,FasterTransformer,I-BERT对比,做了L1 LayerNorm in Fully-8bit和Log-Int-Softmax的消融实验。
4.1. Accuracy Evaluation
4.2. Latency Evaluation
总体latency的提升大概三到四倍,见下图。好像只比I-BERT强零点几ms。
4.3. Ablation Studies
5. Conclusion
In the future, we will consider deploying I-ViT on dedicated integer-only hardware (e.g., FPGAs) to obtain better acceleration performance. Furthermore, we also plan to extend I-ViT to more complex vision tasks (e.g., object detection and semantic segmentation).