摘要: Normalization 层是神经网络的核心组件。在 transformer 中,主流的 RMSNorm 把向量约束到单位超球面上,随后通过一个可学习的缩放系数 γ 做逐维度重缩放,以维持模型的表征能力。然而,RMSNorm 在前向传播中丢弃了输入的范数信息,而一个静态的缩放因子 γ 可能不足以容纳输入数据的广泛变异性与分布漂移,从而限制了性能的进一步提升——尤其在大语言模型频繁遭遇的 zero-shot 场景下。为解决这一局限,我们提出 SeeDNorm:它根据当前输入动态调整缩放系数,从而保留输入范数信息,实现数据相关的、自重缩放(self-rescaled)的动态归一化。在反向传播中,SeeDNorm 保留了 RMSNorm 依据输入范数动态调整梯度的能力。我们对 SeeDNorm 的训练优化给出了详细分析,并针对应用时可能出现的不稳定问题提出了相应的解决方案。我们在不同规模模型上验证了 SeeDNorm 的有效性,涵盖大语言模型预训练以及有监督/无监督的计算机视觉任务。在仅引入极少量参数、对模型效率影响可忽略的前提下,SeeDNorm 相比以往常用的 RMSNorm、LayerNorm 等归一化层,以及 DyT 这类逐元素激活替代方案,取得了一致的性能优势。
1. Intro
Normalization稳定训练、加速收敛,通过对激活施加统计正则来防止梯度爆炸/消失,是 LLM 和 CV 大规模架构里不可或缺的基础模块。
但本文认为,这种稳定是有代价的:LayerNorm/RMSNorm 会丢弃或削弱 input norm 信息,限制表达力、破坏”尺度相关特征”(scale-related features)的保留。虽然引入了可学习参数来恢复部分表达力,但这些参数是静态、输入无关(input-independent),在 zero-shot 泛化这类场景下就力不从心。
saturation activation(tanh 及其动态变体 DyT)。这类函数把输出约束在固定范围内,因而能保留输入的相对尺度/范数。但两个致命缺陷:(1) 极端区域的梯度消失;(2) 反向传播时无法像 RMSNorm 那样按输入范数动态调整梯度,导致优化低效、收敛慢。
能否设计一个方法,同时兼顾——训练稳定性、优化效率、以及保留 input norm 信息?‘
Contributions:
- 提出一个泛化 RMSNorm 的动态 normalization 层,根据当前输入自适应调整缩放系数,保留范数信息、提升对数据变异与分布漂移的适应性;
- 对前向与反向梯度做详尽分析,论证相对现有 normalization 与动态激活的优势,并给出增强训练稳定性的技巧;
- 在 dense 与 MoE 结构的 LLM、以及 CV 任务上做大量实验,证明一致的加速收敛与性能提升,且参数与计算开销极小。
2. Related Works
常见的Norm有:
- BN,沿着Batch维度在每个Channel内部做归一化。BN 在 CV/CNN 里流行,因为它与卷积对齐(同一 kernel 在所有空间位置和 batch 样本上处理同一 channel),并能平滑 loss landscape。但 BN 不适合序列建模,还会在 batch 内跨样本泄漏上下文信息,故 LLM/生成模型很少用。
- 解决 BN 在序列任务的问题,改为沿特征维 对每个样本单独归一化,与 batch size 无关,广泛用于语言建模和 transformer。
- 相比 LN 省掉均值减法,只按 root mean square 归一。训练稳定、性能有竞争力,尤其在大规模 transformer。
文章认为上述Norm的共同局限:稳定性是靠牺牲 input scale 信息换来的,潜在限制表达力。
近期提出的Saturation activation / DyT,用激活函数+可学习标量 α 替代输入相关统计量,保留 γ、β。DyT 在前向显式保留了 x 的范数,用 tanh 约束极端值,把输入向量映射到半径 √D 的超球面内以增强稳定性。但存在梯度消失:
,当 γ 太小、α 过大或过小、或 x 过大时梯度趋 0;而且 是 的高阶无穷小,反传到前面层仍会梯度消失。此外可以证明:在输入范数恒定的假设下 RMSNorm 与 DyT 在对 x 的梯度上等价——反过来说明 DyT 缺乏 RMSNorm 那种按输入范数自适应调整梯度的能力。
证明:令
则
由于 ,我们从梯度等价的角度进行推导:
给定 是一个常数,将其记为 。每个位置上的操作 可以被视为独立计算,上式可以写成如下逐元素微分方程:
求解:
对方程两侧积分,为了记号方便,默认将微分方程中的所有积分常数设为 0:
由于 ,上式左侧必然大于 0,因此可以去掉绝对值符号。然后我们有:
由于,我们有:
由于 DyT 包含一个可学习缩放系数,常数 可以被吸收到中。类似地, 也可以并入中。
因此,尽管 DyT 在前向传播中保留了输入范数,但与 RMSNorm 相比,它在反向传播期间失去了基于 x 的幅值动态调整梯度尺度的能力。相比之下,本文提出的方法在前向和后向阶段都保留范数信息,使模型在整个优化过程中具有数据依赖的、自重缩放梯度。
3. Self-Rescaled Dynamic Normalization (SeeDNorm)
定义:
对单 token :
- :RMSNorm 的静态缩放,1-初始化;
- :self-rescaling 参数,0-初始化;
- : 与 做点积得标量(),再过 ;
- ():把那个标量广播乘到 α 向量上,得到 的逐元素 rescaling 矩阵;α 的初值可作超参调(语言任务里初始化为 1)。
- 默认用 tanh,输出锁在 ,保证 x 的大 outlier 不会显著影响缩放系数。
用的是未归一化的原始 x**,** RMSNorm 把 除掉丢了,SeeDNorm 让 通过在 β 方向上的投影 重新进入前向,再经 tanh 有界化。从而实现”preserve input norm information”。
是每 token 一个标量 gate, 是向量,所以动态修正项 让每个 channel 得到不同但成比例的调整(同一个标量 gate 按 α 的形状分布到各维)。γ 是静态基线,σ·α是随 token 变化的动态偏移。
可替换 transformer 里所有 normalization,包括 QKNorm。 用 1 初始化、 用 0 初始化, 由超参决定。训练时对 γ 沿用 baseline 的正则策略,默认不额外加 weight decay;但对 、 weight decay,有利训练、缓解过拟合。
3.1. Analysis of SeeDNorm
对于Fwd,RMSNorm原文中已经讨论了它的稳定性,此处不再进一步分析,重点讨论反向传播,即各个参数和输入的梯度。
Invariance Analysis
SeeDNorm 不严格 scale-invariant,但对输入缩放不敏感。当 : 部分里 k 约掉不变,只有 self-rescaling 矩阵从变成。求导:
- x 很大时 ,,f 变化极小;
- x→0 时 达最大值 。
所以设计上:初始化为 0使初值为 0(初始等价于纯 RMSNorm),并对 、 加 weight decay;x 接近 0 时 f 主要由 主导。
Gradient Analysis
记 ,四个梯度:
的梯度:只含 scale-invariant 的 (因为 ),因此不受异常大/小 x 影响,训练天然稳定,无需额外处理。
的梯度:也含 ,但乘了 。用 tanh 时,x 异常大时 被锁在 1 内可以防梯度爆炸;x 异常小时梯度变小但仍能正常更新。注意:直接乘在的梯度里,又直接影响的梯度,所以和不能同时初始化为 0。
的梯度:。x 异常大时 cosh 是 x 的高阶无穷小, 梯度几乎为0;x 异常小也趋向0;两头都避免爆炸。因为通常被包在或 里(范围受限),而 是直接相乘的,所以把 初始化为 0,让 的梯度在训练早期从 0 起步以增强稳定;又因为几乎所有梯度都含 、,需要用 weight decay 控制它们的尺度防止持续增大导致梯度过大。
x 的梯度最关键,决定它像不像 RMSNorm:x 是上一层的激活,其梯度要回传更新前面的层。理想行为是”x 大则回传梯度小,x 小则回传梯度大”。
设 且 k 很大:第一项接近0;; 不变;因此整个梯度由 主导,梯度按 k 同比例缩小。
这正是 RMSNorm 的 norm-adaptive 梯度性质,也是 DyT 缺失的。k 很小时,第二项远大于第一项,同样由主导。结论:SeeDNorm 反传具备良好的自适应梯度调节。
3.2. Multi-Head SeeDNorm
与 影响 三者的梯度。前面只分析了极端值,但实际训练里极端值罕见;为在非极端条件下也稳,策略是降低 的方差。
Theorem:高维空间中,两个随机向量点积的方差正比于维度 D。 证明:假设有两个 D 维随机向量 和 。它们的分量是独立同分布随机变量,并且满足:
那么 ,令,我们有:
因此,,它与维度大小成正比。
实际做法是:把 x 和 各切成 n 个 sub-vector,逐 head 算点积再拼回原维度:
每个点积维度降到 ,从而把方差压下去。这里 、 也变成 multi-head 形式,目标是降低梯度方差。
4. Experiments
总原则:把 baseline 里所有 normalization / saturation activation 全部换成 SeeDNorm。
4.1. Large Language Models
MoE 用 OLMoE,dense 用 OLMo2。语料严格对齐原实现(OLMoE-mix-0924 / OLMo-mix-1124)。两者都用 RMSNorm,除 attention/FFN 输入外,还在 output norm、QueryNorm、KeyNorm 用。全部换成 SeeDNorm,且 QKNorm 在每个 attention head 内做。语言任务初始化为 1。
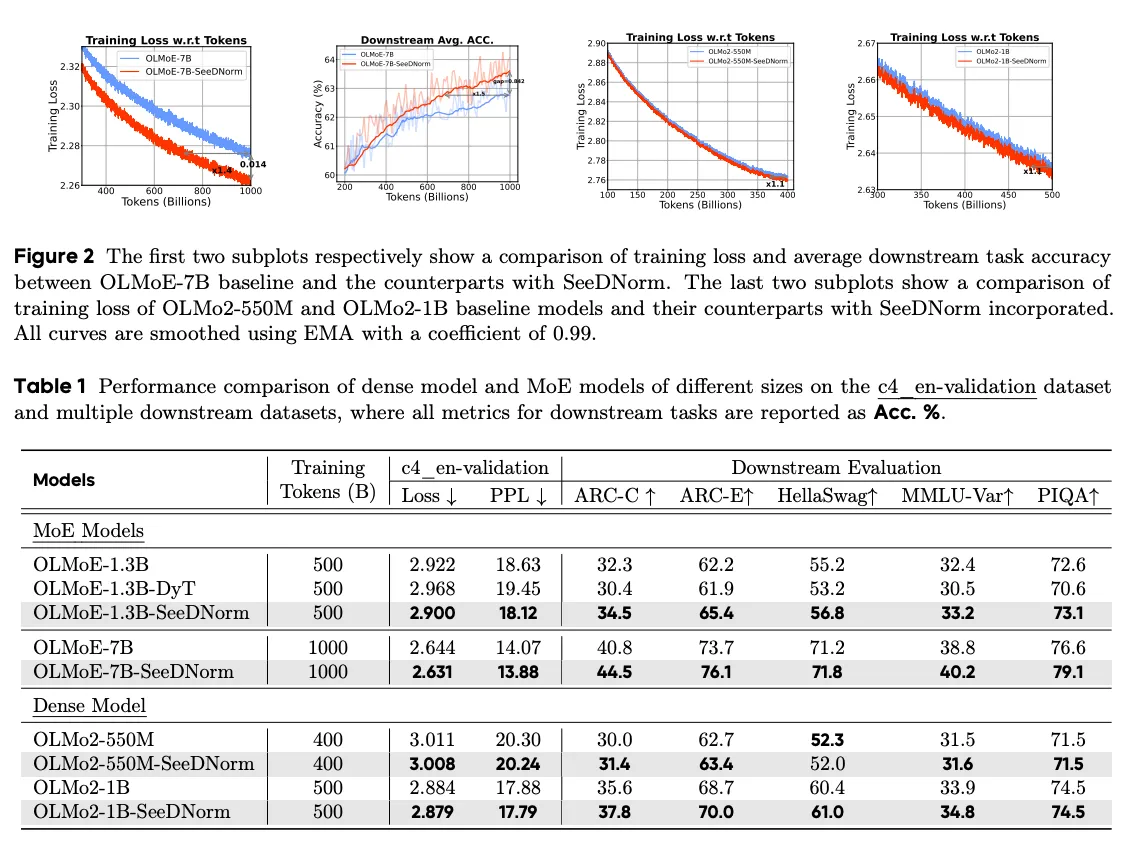
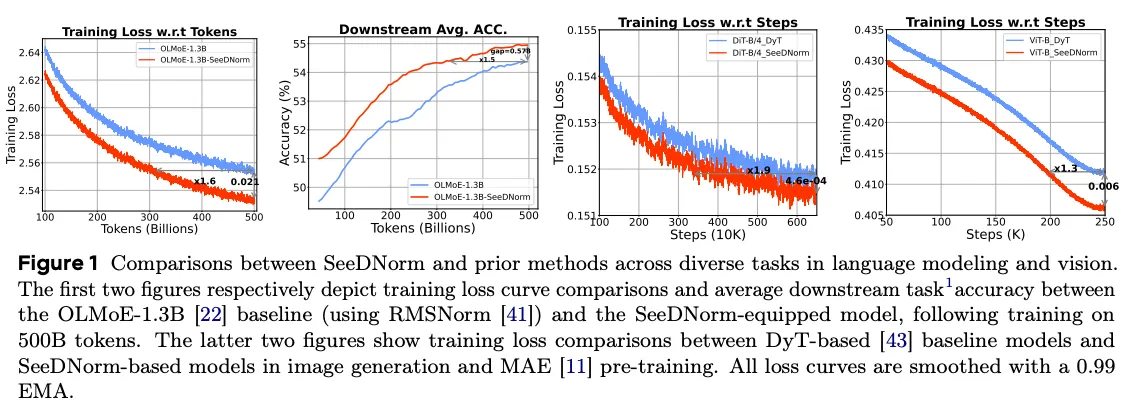
MoE:SeeDNorm 显著加速收敛;且随 token 增多,loss 相对 baseline 的改进越来越大,而把 OLMoE-1.3B 换成 DyT 反而收敛变慢、性能退化(loss 2.968、PPL 19.45,多数下游下降)——直接对照验证了 saturation activation 的缺陷。
Dense:收益缩小,但仍然有收益。作者解释:dense 模型不需要动态激活参数、训练更稳、每个参数被充分训练,从而削弱了 SeeDNorm 带来的加速收敛优势;但在 zero-shot(ARC-C/ARC-E)上仍显著提升。MoE 的动态架构更能放大 SeeDNorm 的优势,似乎证明动态 normalization 与动态路由(MoE)之间存在协同。
4.2. Computer Vision Tasks
SeeDNorm无法直接替换AdaLN,缺乏条件预测。提出:
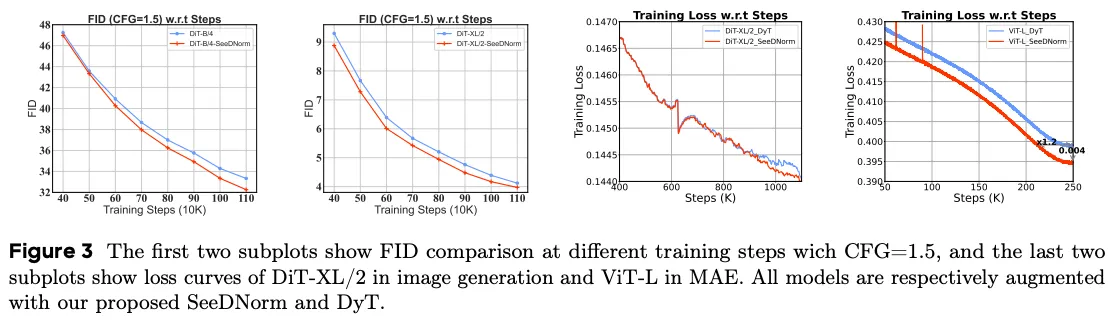
由于 DyT 已经强过 DiT baseline,作者直接与 DyT 比,cfg-scale=1.5。FID 和 loss 都优于 DyT。
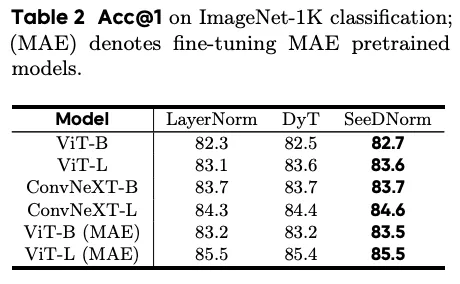
Supervised(ViT、ConvNeXt):SeeDNorm 优于 DyT 和 LayerNorm(ViT-B 82.3/82.5/82.7,ConvNeXt-L 84.3/84.4/84.6)。
Self-Supervised(MAE on ViT):显示 SeeDNorm 显著加速 pretraining 收敛,fine-tune 也占优(ViT-B(MAE) 83.2/83.2/83.5)。
4.3. Ablation Study
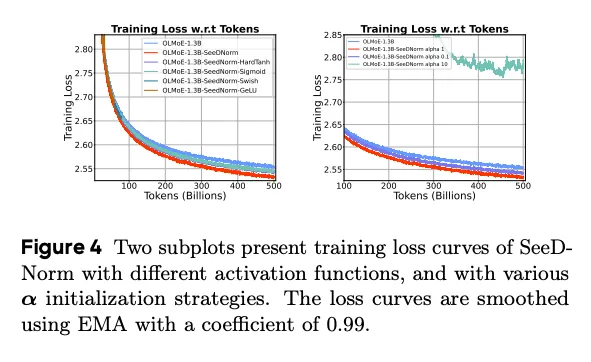
- σ 的选择:默认 tanh。无界激活(GeLU、Swish)不收敛;有界的 sigmoid/tanh/hardtanh 都能收敛且都超 baseline,tanh 最好。这印证了”σ 必须有界”是设计约束。
- α 初始化(0.1 / 1 / 10):α=10 严重损害稳定性、最终性能差;小 α 保稳定;适度偏大(α=1)加速收敛效果最好。
- α 向量 vs 标量:标量时 rescaling 只能对整个向量均匀调整,失去 element-wise,性能退化但仍胜 baseline。
- β 与 x 的乘法类型:默认点积优于 element-wise 乘(后者 loss 2.909,下游多数更差)——点积表达力更强。
- 移除 α/β/γ:移 α → 非 element-wise(同标量 α);移 β → 失去调整 σ 形状的能力,与 α 的运算退化成矩阵乘;移 γ → SeeDNorm 等价于直接用 self-rescaling 矩阵替换 RMSNorm 的缩放因子。三者移除都比完整版差但仍普遍超 baseline。
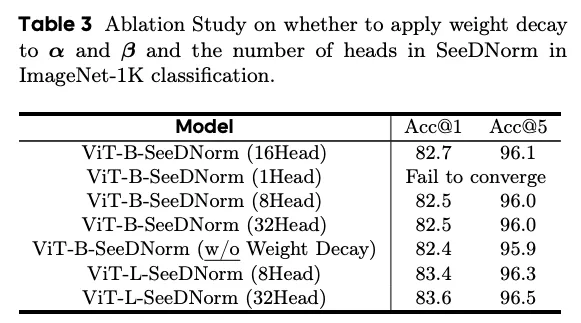
- multi-head 数:1 head 不收敛;head 增多提升性能,但过多会降低梯度多样性反而变差(16 head 最佳 82.7,8/32 head 均 82.5)。大模型(hidden dim 更大)可用更多 head。
- α、β 的 weight decay:去掉后性能变差(82.7→82.4),实验验证了 3.1 的理论分析。
5. Conclusion
SeeDNorm 以输入为条件动态调整缩放因子,前向纳入被 RMSNorm 忽略的 input norm 信息,增强对多样输入的适应性;反向保留按幅度动态调梯度的能力。在语言与视觉多任务上更快收敛、更优性能,呼吁更多关注改进 normalization 层本身。